
Advanced Security Information Model Schemas (ASIM)

Microsoft Sentinel, the SIEM solution that Microsoft Azure offers, ingest data from many sources, like firewalls, domain controlers, device logs, etc. When all that data is in Microsoft Sentinel, it is stored in tables with specific columns, but if you ingest data from several different sources, understanding each of the tables and their custom columns may be difficult.
Users use Advanced Security Information Model (ASIM) parsers instead of table names in their queries to view data in a normalized format, and to include all data relevant to the schema in your query.
What is normalitzation? Normalitzation is the process of converting data collected from different sources to a uniform format with specific and consistent fields.
The ASIM has three main components:
- Schemas: Schemas are the “tables” that represent an event in a normalized column naming convention and a standard format for the field values
- Parsers: Parsers are functions that map existing data into the normalized schemas using KQL functions
- Content: All the analytics rules, workbooks, queries, etc. that use ASIM parsers
Let’s see how it works using examples.
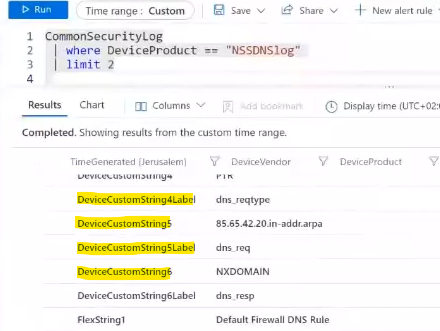
In this picture we can see custom logs obtained from a custom device. The table “CommonSecurityLog” is not normalized and the column names are not normalized, there are a lot of custom attributes that make it difficult for us to create queries, workbooks, detection rules, etc., that work for this device logs.
Instead of searching for DNS events with specific queries for each device, we can use the builtin ASIM parser _Im_Dns , that will search DNS events from all sources and return them in a normalized table:
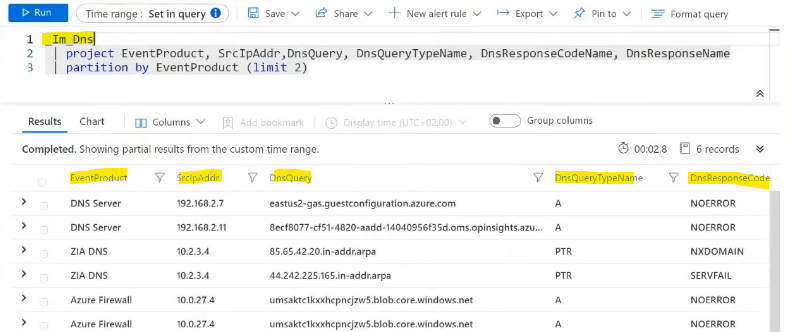
These ASIM parsing funtions change data at query time, so the original data is not modified an the unparsed data will remain unmodified.
Most of the parsers are already built in in each Microsoft Sentinel workspace (you can’t modify them), but you can also deploy specific parsers to your workspace.

Writing queries while using ASIM parsers
When you want to do a query using an ASIM parser, you must:
- Use the ASIM function as a table name
- Use normalized field names
- Use normalized values

Parser hierarchy and naming conventions
We can classify ASIM parsers in two types: Unifying and source-specific parsers.
The unifying parser is to ensure that all data (from all sources) for the relevant schema is returned. Since a unifying parser has to return data from different sources, it uses source-specific parsers to work to function. A source-specific parser is specific for a single product/device and knows how to parse the data that the product returns.
Unifying parsers are named using th _Im_<schema> convention (when they are built-in). If they are workplace deployed, they use the im<schema> convention.
For source-specific parsers, the naming conviention is _Im_<schema>_<source> for built-in parsers and vim<schema><source> for workspace deployed.
When using ASIM, you can use filtering parameters to improve performace by filtering before parsing. Each schema has a set of filtering parameters. For example, the following query uses ASIM without filtering parameters:
1
2
3
4
_Im_Dns
| where TimeGenerated > ago(1d)
| where ResponseCodeName =~ "NXDOMAIN"
| summarize count() by SrcIpAddr, bin(TimeGenerated,15m)
We could obtain the same results faster by using filtering parameters:
1
2
_Im_Dns(starttime=ago(1d), responsecodename='NXDOMAIN')
| summarize count() by SrcIpAddr, bin(TimeGenerated,15m)
More information here
Developing Custom Parsers
There are situations where you may want to develop a source-specific parser because it doesn’t exist in Microsoft Sentinel a parser for a device you have.
- In order to be able create a parser, you first need to understand the log format so you should start by collecting a representative set of log samples.
- Once you have understood the log formats, you need to identify the mandatory and recomended fields that the schema that you want to use needs.
- The next step is to develop the parser in KQL. A parser query has three parts:
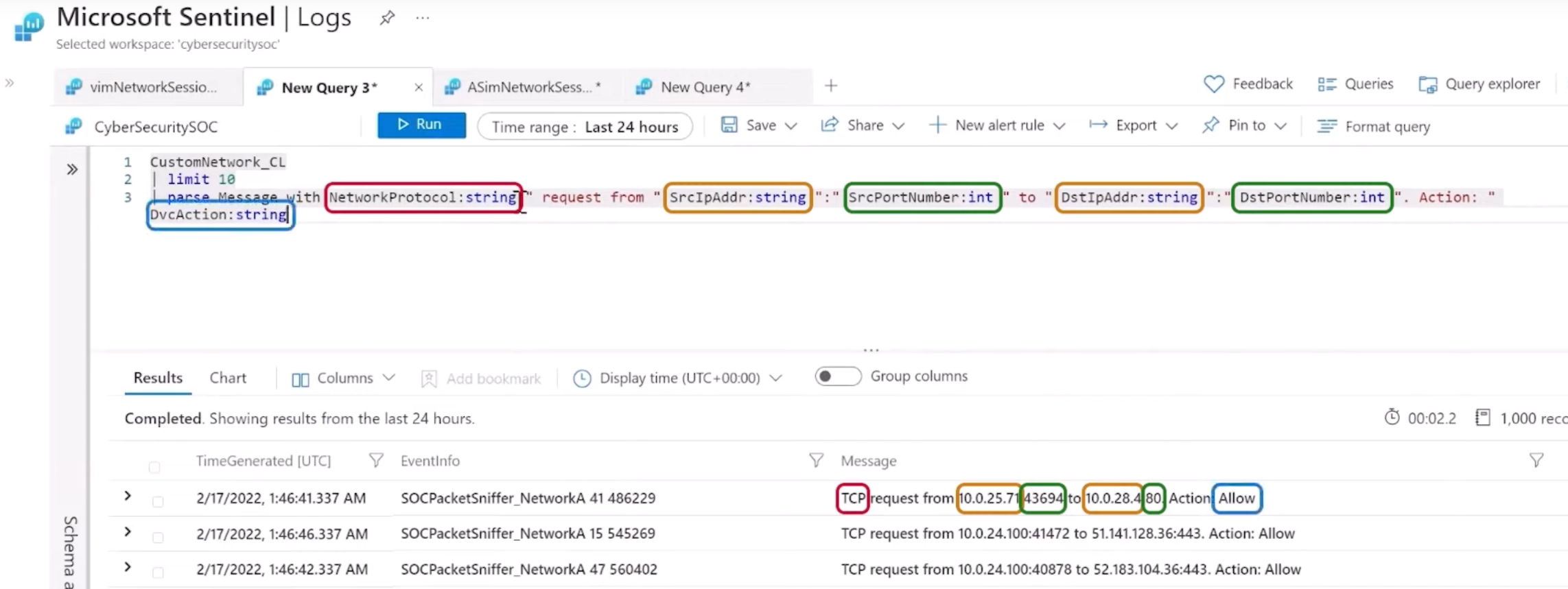
- Filtering: A parser should first filter only the relevant records. You can filter using the
whereKQL operator. More detailed information here. - Parsing: Once the query selects the relevant records, we need to parse them and divide the fields into normalized ones. There are different KQL operators that allows parsing, such as
splitorparse. A full list can be found here.
![Untitled]()
- Normalizing: Once the data has ben parsed, we should normalize the data and renaming the fields. You can also create additional fields that the original source doesn’t contain but we can generate. You can find more information and techniques for normalizing here.
![Untitled]()
- Filtering: A parser should first filter only the relevant records. You can filter using the
- Once the source-specific parser has been created, we can deploy it manually by copying them to the Azure Monitor Log page and saving the query as a function.
- You can then add this source-specific parser into a existing unifying parser so the custom device you have can be now also considered when using the unifying parsers.
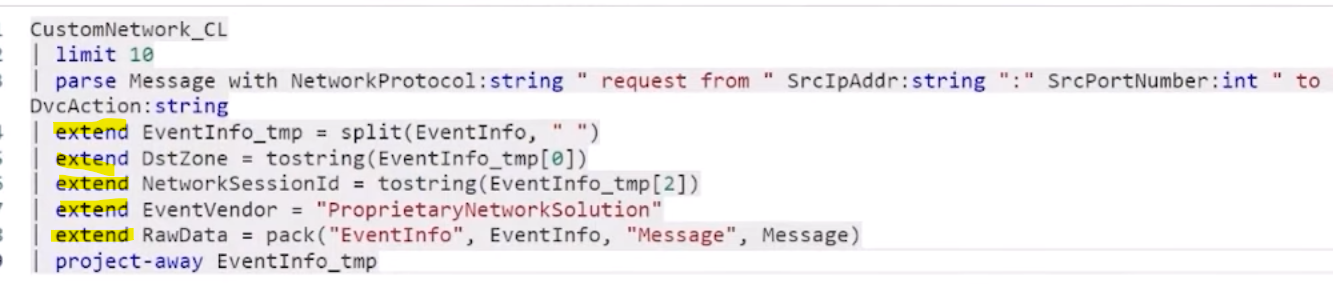
A parser should not filter by time, since the query that uses the parser is the one that will use the time filter